Importing Transforms
The Data Studio supports running custom Python code to transform the sensor data in your project and generate new columns in your time series graph. Below we will go over how to build a custom Python transform for your project.
Requirements
Running Python transforms requires Python version 3.7 or greater to be installed on your computer. Install python from https://www.python.org/downloads/
Install the SensiML Python SDK by running the following command
pip install SensiML
Example Code
Download the zip file
Unzip the file and open
symmetric-moving-average.pyto view and edit the source codeImport the Python file through the Data Studio
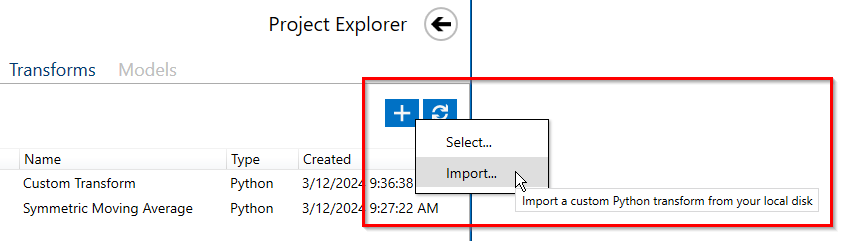
API Overview
The Data Studio has several built-in transforms, but also allows users to import their transforms written in Python. Imported Python transforms must implement two APIs:
get_info_json()
transform(data, params)
The get_info_json API returns the JSON serialized input contract as a string. The Data Studio UI uses this get_info_json response to dynamically generate a parameters selection screen for the transform.
The transform API is responsible for taking the input data and parameters from the Data Studio and returning a data series object, a dictionary with the keys being the name of the sensor and the values being a tuple of two arrays. The first array is the sequence or X values and the second is the transformed data or Y Values.
Several helper functions demonstrate how to take the input from the Data Studio and turn it into simple Python functions, as well as some helper functions for turning Python objects back into the format the Data Studio will understand.
Input Contract
The input contract is a list of dictionaries. Each item in the list describes an input parameter that the user can configure. The properties of the dictionary are
name: The name of the parameter
display_name: The name to display in the UI, defaults to name if not included
type: The Type of the parameter (bool, int, float, string)
default: The default value to use for the parameter
description: Description of the parameter that will show up in the UI
range: A tuple of min and max values used to limit the input parameters min and max value, eg [0,100] would mean only values from 0 to 100 would be acceptable
options(optional): A list of options that can be used to create a dropdown selection
num_columns(Reserved): This option is reserved for the “columns” input parameter. It specifies how many input channels are allowed in this function. -1 or empty means unlimited. A specific number like 1,2,3,4 means that number is required.
get_info_json API
The get_info_json API returns the input contract, along with some other information about the transform. When the transform is loaded, this function is called to populate the database with information about the transform. The get_info_json will return a JSON serialized string. Typically, we call the get_info function which returns a dictionary. The get_info dictionary typically will have
name: Name of the Function (used in the UI as the default)
type: Specifies the type of object this is
subtype: Specifies a subtype, this is used for organizing transforms
description: A description of the function that will be shown in the UI
input_contract: A description of the parameters and inputs including types, bounds and options
output_contract: Used to include information about the output of the function
Here is an example of the get_info API for the Symmetric Moving Average Python transform included in the Data Studio.
def get_info_json() -> str:
return json.dumps(get_info())
def get_info() -> dict:
return {
"name": "Symmetric Moving Average",
"type": "Transform",
"subtype": "Filter",
"description": "This transforms performs a symmetric moving average filter on the input signal with a filter length of filter order 2*l+1",
"input_contract": [
{
"name": "columns",
"display_name":"Input Columns",
"type": "list",
"num_columns": 1
},
{
"name": "filter_order",
"display_name":"Filter Order",
"type": "int",
"default": 10,
},
{
"name": "normalize",
"display_name":"Normalize",
"type": "bool",
"default": False,
},
],
"output_contract": [{}],
}
And here is a screenshot of the UI that is generated.
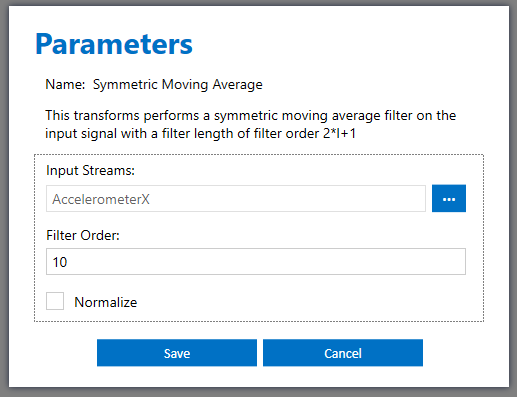
When the user hits save, a params.json file is created inside the imported transforms folder. For this function, here is the params.json file
{
"input_contract": {
"filter_order": 10,
"normalize": false,
"columns": [
"AccelerometerX"
]
}
}
Whenever the user updates parameters and saves, this params.json file will be updated.
Transform API
The Data Studio will call the transform API of the imported Python function to apply the transform to the sensor data. The Data Studio passes two parameters, the data object and the parameters object. The SensiML Python SDK includes helper functions for converting the objects passed in from the Data Studio into standard Python objects. Let’s look at an example
This is the main transform block that the Data Studio calls. We use the built-in convert_to_datasegments function call on the data to turn that into a data_segments object. This allows us to cast the objects created in the Data Studio to Python types that are easy to work with.
def transform(data, params):
data_segments = convert_to_datasegments(data)
params = validate_params(get_info()['input_contract'], params)
result = transform_data(data_segments, params)
converted_result = to_data_studio_dataseries(params['columns'][0], result)
return converted_result
The convert_to_datasegments function is as follows.
def convert_to_datasegments(data: dict, dtype=np.float32)
converted_data = {}
for k, v in dict(data).items():
if not k:
continue
converted_data[k] = {"X":[float(item) for item in v[0]],
"Y":[float(item) for item in v[1]]}
return converted_data
It returns a dictionary where the key of the dictionary is the sensor name and the items are a dictionary of two keys X and Y which each have an array of floats in them representing the sequence and sensor values respectively.
Note
Note: Sensor columns can have different X values
The validate_params function validates that the parameters passed in are the required types and ranges. It also checks that all required parameters are passed in.
The transform data function is where the user transform takes place. Here we make use of the parameters that are passed in and modify the sensor data.
def transform_data(data_segments, params):
input_column = params['columns'][0]
data = np.array(data_segments[input_column]['Y'])
if params['normalize']:
data = normalize(data)
return symmetric_ma_filter(data, params['filter_order'])
def symmetric_ma_filter(data, filter_order=3):
"""
Performs a symmetric moving average filter on the input column,
creates a new column with the filtered data.
Args:
data: DataFrame containing the time series data.
filter order: the number of samples to average to the left and right.
Returns:
input data after having been passed through symmetric moving average filter
"""
ma_filtered = np.zeros(len(data))
for i in range(len(data)):
if i < filter_order:
ma_filtered[i] = data[i : i + filter_order + 1].mean()
elif i > (len(data) - filter_order):
ma_filtered[i] = data[i - filter_order :].mean()
else:
ma_filtered[i] = data[i - filter_order : i + filter_order + 1].mean()
return np.round(ma_filtered)
def normalize(data):
"""
Normalizes the sensor data
Args:
data: DataFrame containing the time series data.
filter order: the number of samples to average to the left and right.
Returns:
input data after having been passed through symmetric moving average filter
"""
return (data - data.mean())/np.std(data)
Finally, we all the to_data_studio_dataseries and return the data to the Data Studio. The Data Studio data format is a dictionary, where the key is the name of the sensor and the values are a tuple of X, Y Python lists.
def to_data_studio_dataseries(name, data, time=None):
if time is None:
time = list(range(len(data)))
if len(time) != len(data):
raise Exception(f"Time and Data are not the same length {len(time)} {len(data)}")
return {name: (time, data.tolist())}