Guitar Note Audio Recognition

Overview
In this tutorial, we are going to build a model to classify guitar tuning notes that can run entirely on a microcontroller using the SensiML Analytics Toolkit. This tutorial will provide you with the knowledge to build an audio recognition model. You will learn how to
Collect and annotate audio data
Applying signal preprocessing
Train a classification algorithm
Create firmware optimized for the resource budget of an edge device
What you need to get started
We will use the SensiML Analytics Toolkit to handle collecting and annotating sensor data, creating a sensor preprocessing pipeline, and generating the firmware. Before you start, sign up for SensiML Community Edition to get access to the SensiML Analytics Toolkit.
The Software
SensiML Data Studio (Windows 10) to record and label the sensor data.
We will use the SensiML Analytics Studio for offline validation and code generation of the firmware
(Optional) SensiML Open Gateway or Putty/Tera Term to view model results in real-time
Hardware
Select from our list of supported platforms
Use your own device by following the documentation for custom device firmware
Firmware
If you are using one of our supported platforms, you can find the instructions for getting the firmware
Collecting and Annotating Sensor Data
Building real-world Edge AI applications requires high-quality annotated data. The process can be expensive, time-consuming, and open-ended (how much data is enough?). Further, applying the correct annotations to time series data is complicated without a clear data collection protocol and tooling.
The SensiML Data Studio makes it easy to collect, annotate and explore their time-series sensor data. We will use the Data Studio to collect and annotate audio data in this tutorial.
Import Project
Download the project
Import the project to your account using the Data Studio.

This project includes some labeled audio files. You can view the audio files by opening them in Project Explorer in the top left corner of the navigation bar.
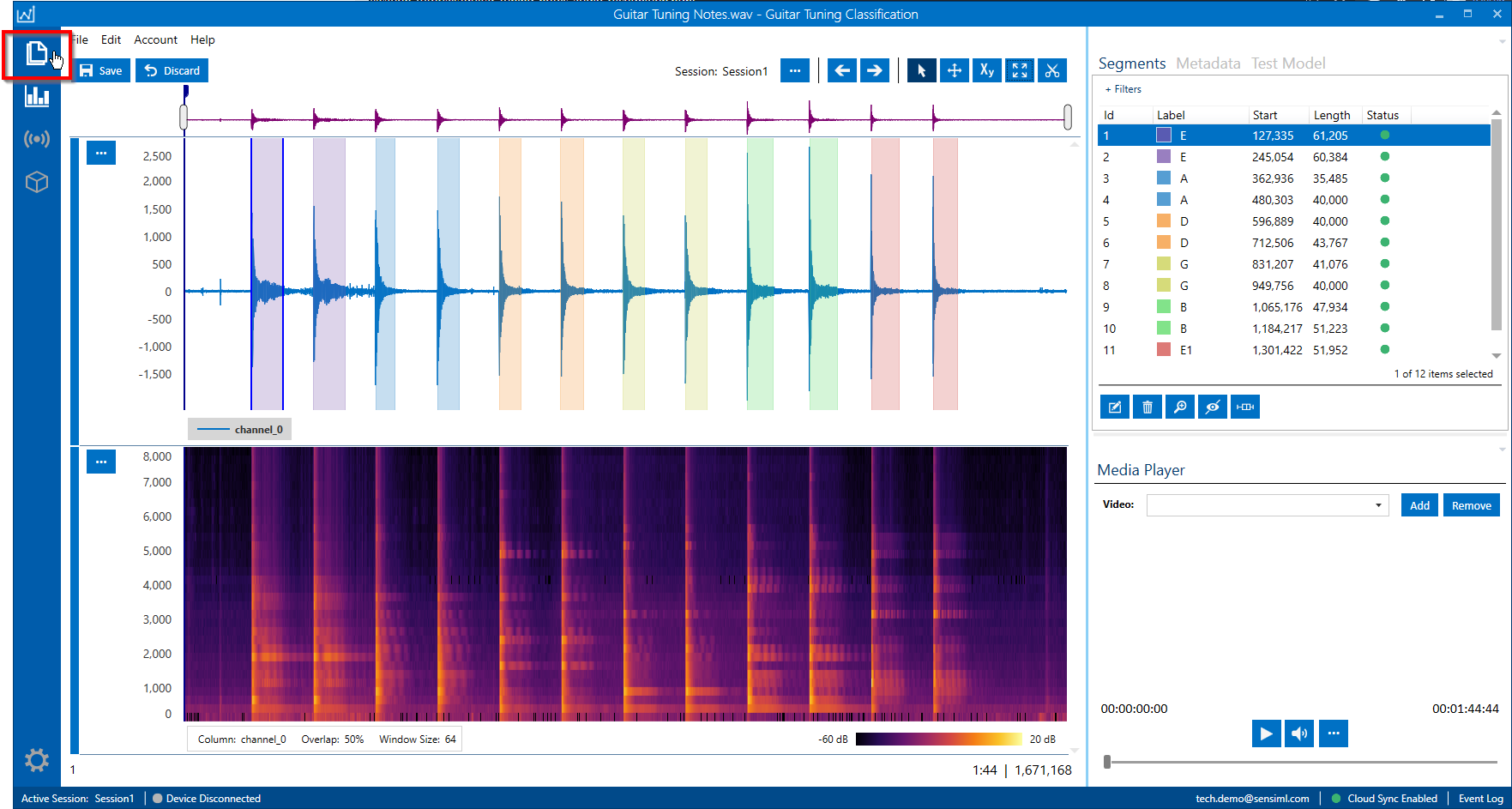
Collect Data
To collect new data, click on the Live Capture button in the left navigation bar
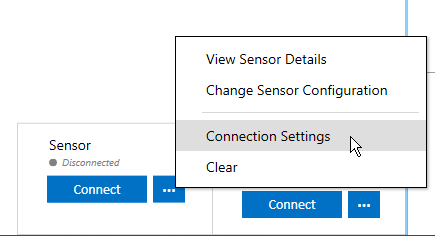
Select a sensor configuration for your device and then you can immediately start collecting audio data. Next, we are going to connect the board over USB Serial. Then click the connection settings to set the COM port to connect over.
Click Scan and select the COM port assigned by your computer for your board.
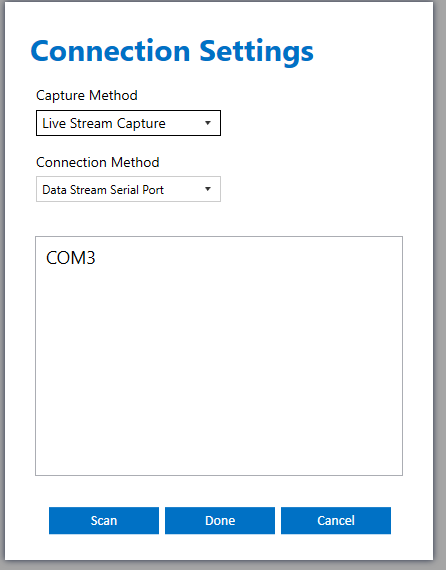
The Data Studio will connect to the board and stream audio data.
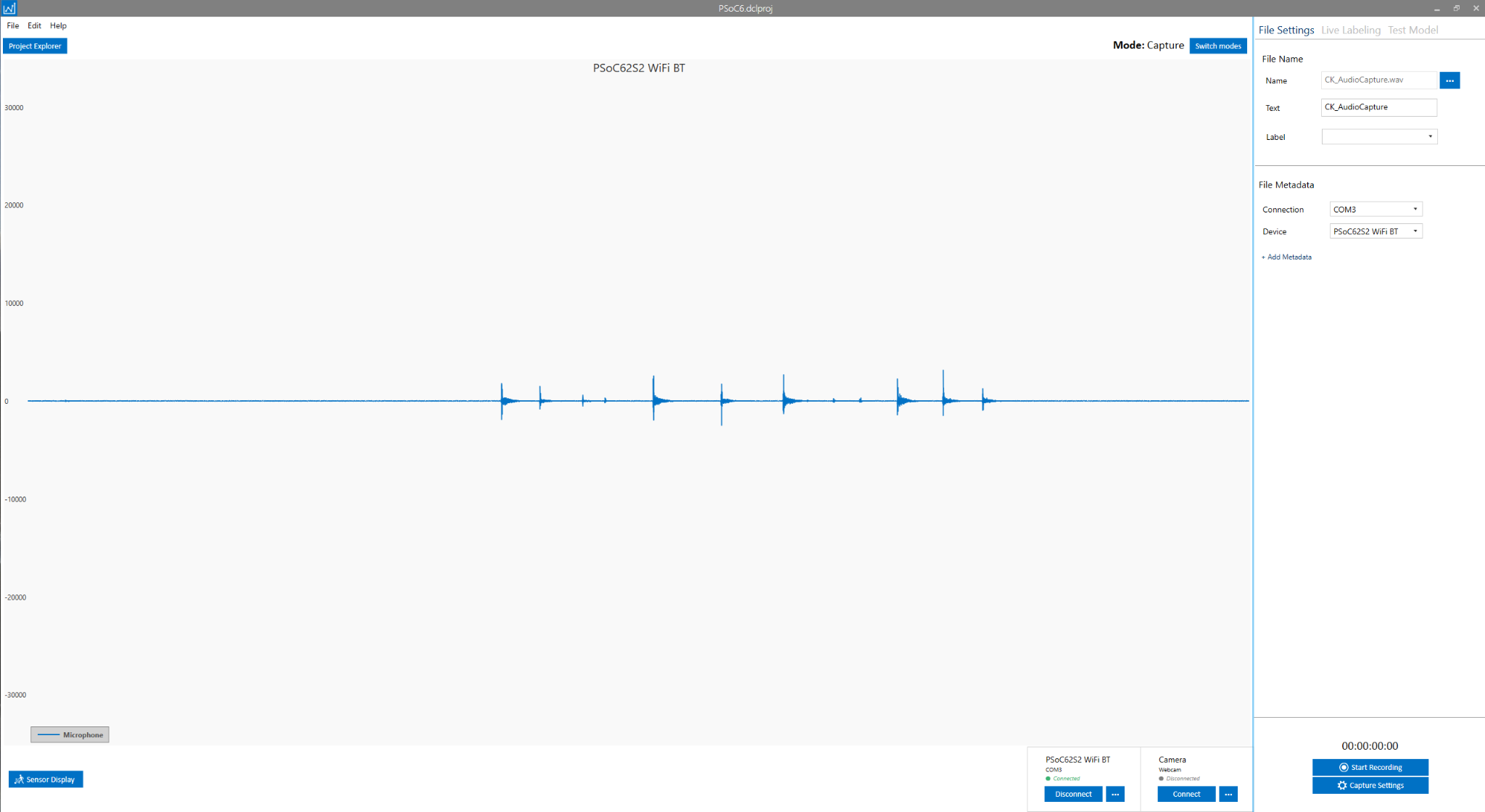
For this demo, we used this YouTube video https://www.youtube.com/watch?v=DlMrl3EQ1bs to record the audio from our speakers. Begin playing the video through your speakers and click the Start Recording button in the Data Studio to capture the audio data from the microphone.
Click the Stop Recording button to finish the recording. Review the confirmation screen and update any information, then click Save
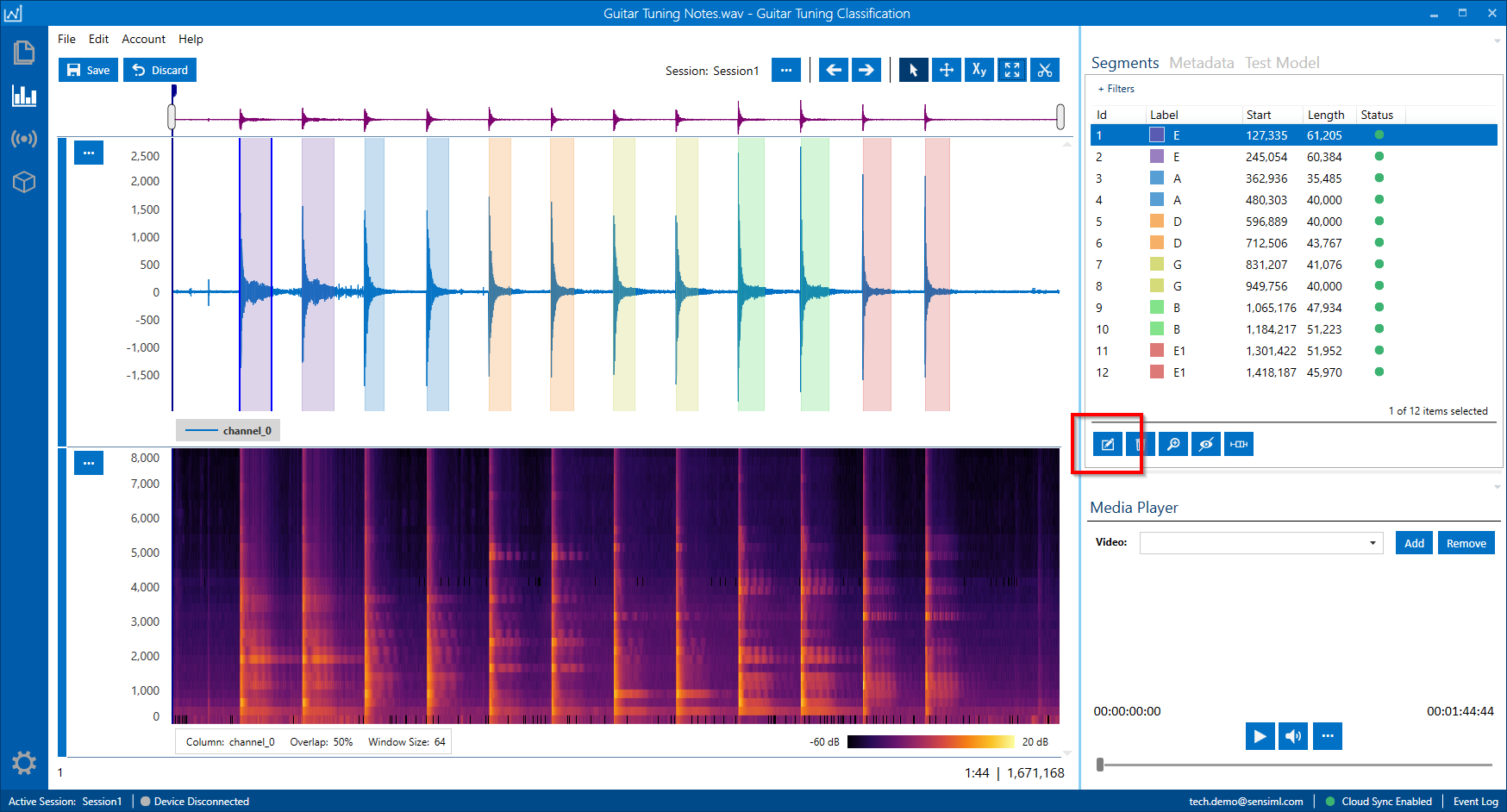
Annotate Data
Open the Project Explorer and open the newly captured file by double-clicking on the file name. You can add a Segment by right-clicking and dragging around the area of interest. Then you can apply a label by pressing Ctrl + E or clicking on the edit label button under the segment explorer. Once you have labeled the file, click Save.
Note
You can label more than one segment at the same time. Select multiple segments in the Segment Explorer, click Ctrl + E, and select the label.
For more information on the capabilities of the Data Studio, see the Data Studio documentation
Building a Model
Now we are going to build a model to classify the guitar notes. To build the model we will use the SensiML Analytics Studio. Go to https://app.sensiml.com and sign in. Then open the project Guitar Tuning Classification project by clicking on the icon .
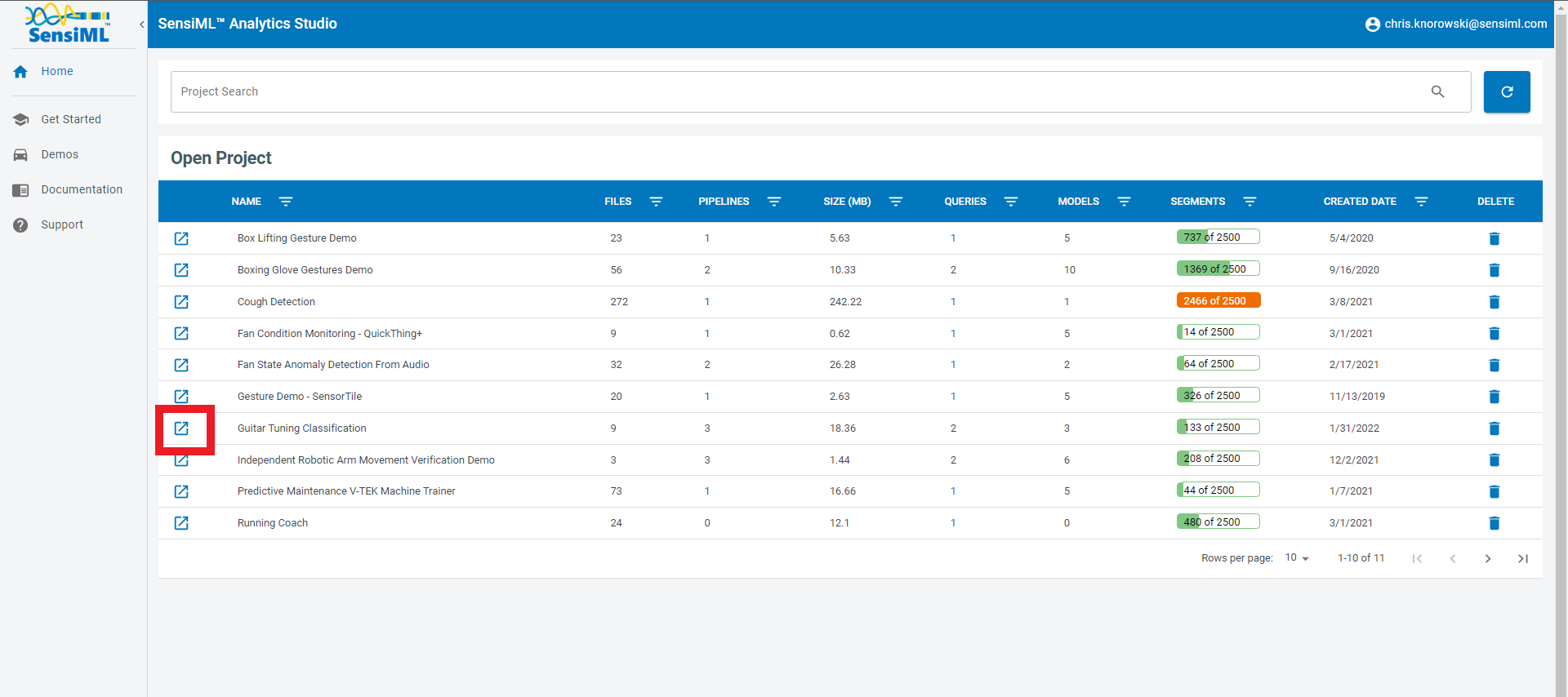
Once the project opens, you will see the overview screen. Here, you can see a high-level view of this project. You can also add notes (with markdown formatting) to the project description.
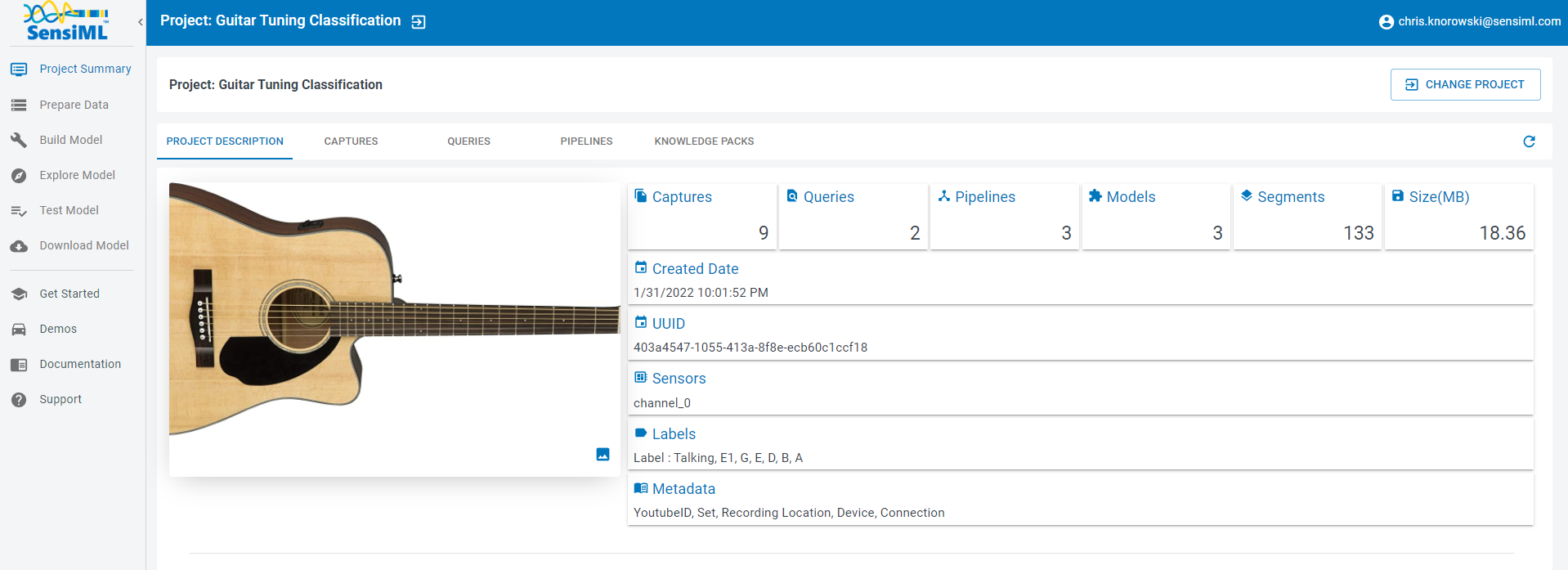
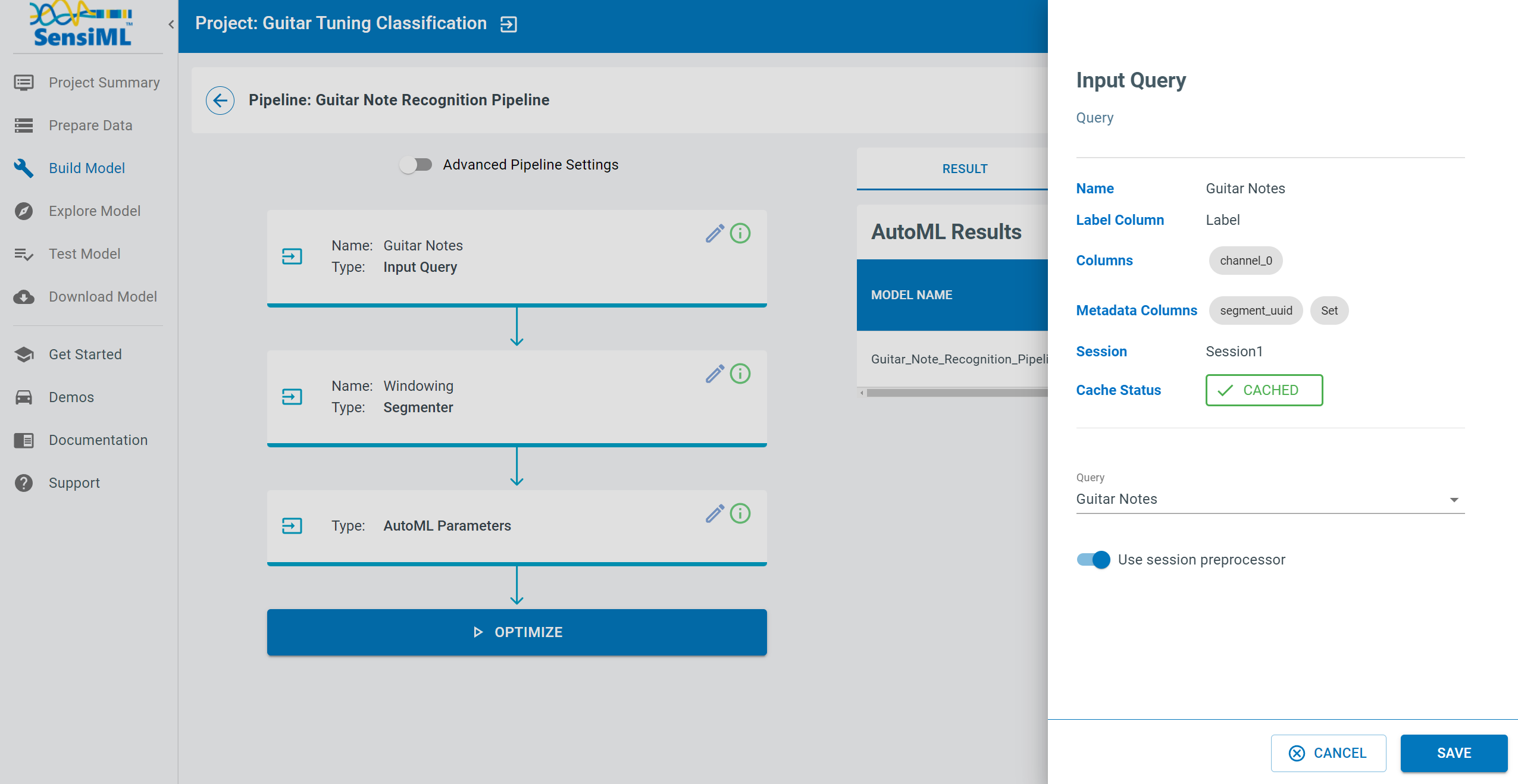
Create a Query
We will create a query to select the training data for our machine learning pipeline. Click on the Prepare Data tab on the left to start building a query.
To create a query
Click the Add New Query button
Set the fields to match the image below
Click the Save button.
Note
You can build the cache for this query by clicking the build cache button at the top. If you don’t create the cache now, it will build during the pipeline creation. The cache will not change until you rebuild, even if you change the project data. You can rebuild the cache at the Project Summary -> Query Tab.
Create a Pipeline
Now we will build a pipeline that will train a machine learning model on the training data. Click on the Build Model tab on the left. Then click on the Create New Pipeline button under the Create New Pipeline card.

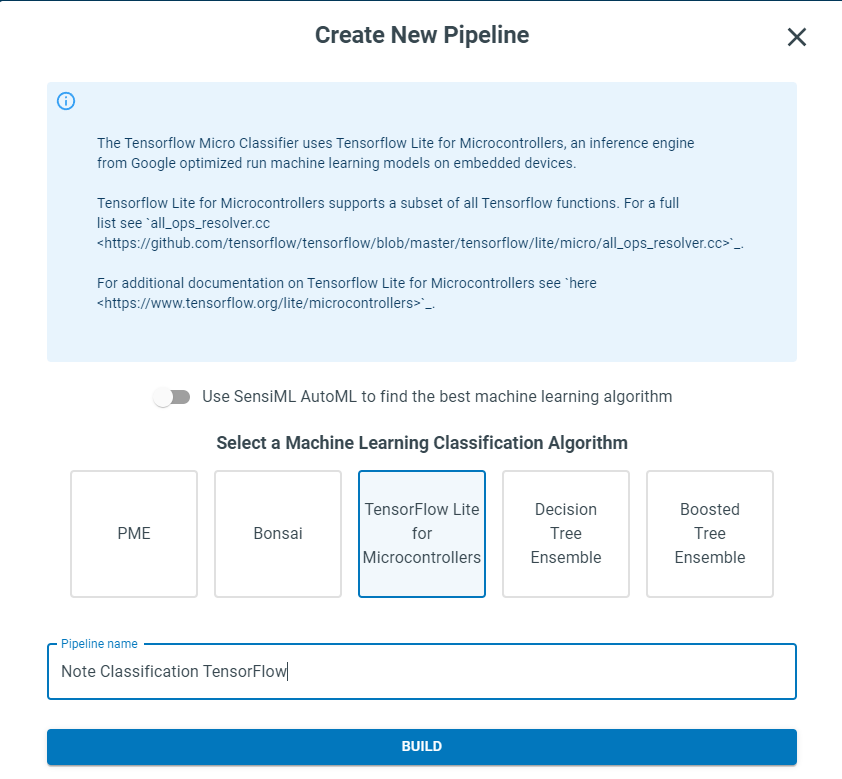
For this tutorial, we will use TensorFlow to build a neural network. To do that,
Click disable SensiML AutoML toggle
Select the box for TensorFlow Lite for Microcontrollers
Enter a pipeline name.
Click Build
This creates a template pipeline that we can edit.
The first thing this screen will ask is that you select a query. Select the Query that you just created in the prepare data screen.
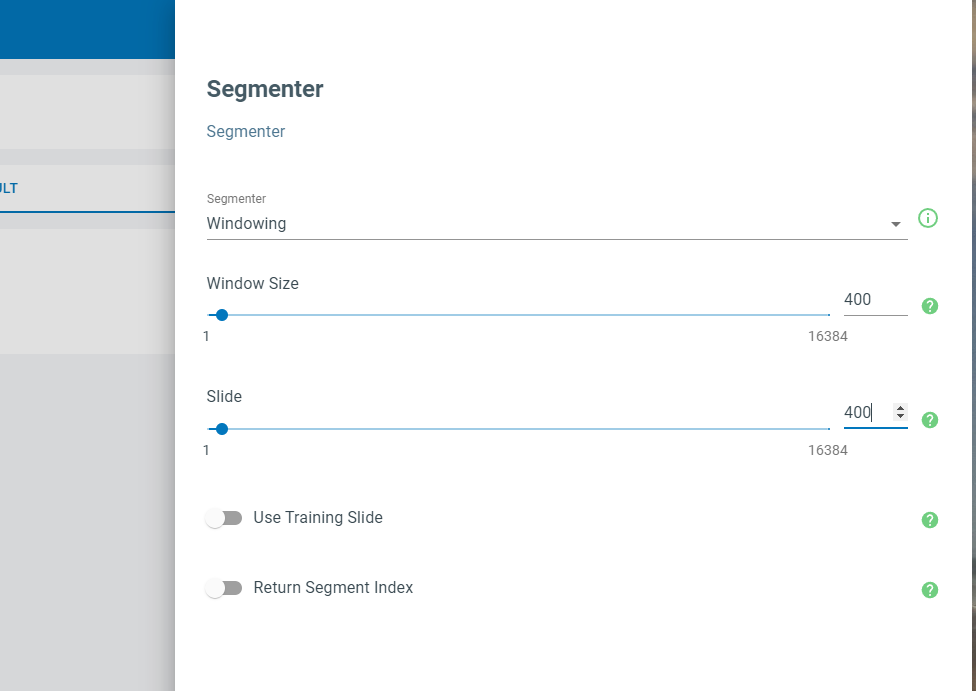
Next, the Segmenter screen will open. We will select the sliding window segmentation algorithm. Set window size to 400 and set slide to 400, then click the Save button at the bottom of the screen.
The next step is to add a filter and some feature extractors to the Pipeline.
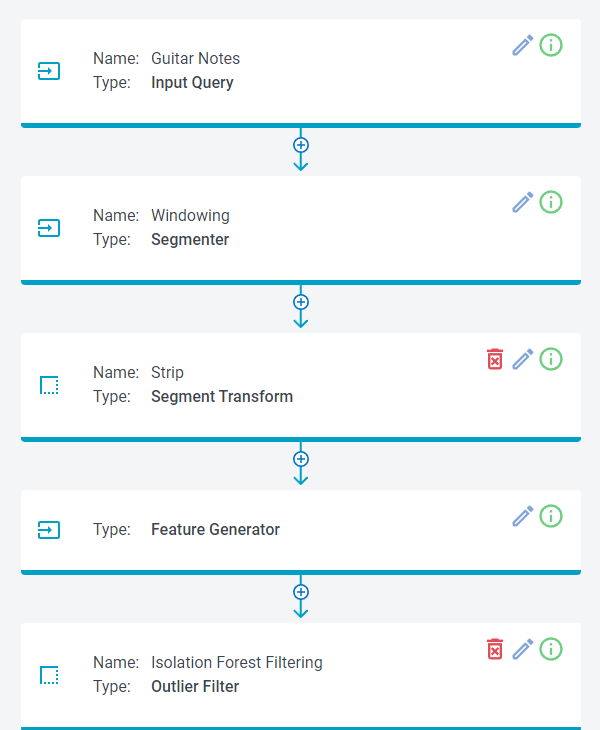
We will go ahead and remove the Strip transform that is there and replace it with an Energy Threshold Filter. To do that, click the trash icon on the Strip card.

To add the Energy Filter Function, click the  icon between the Segmenter and Feature Generator.
icon between the Segmenter and Feature Generator.
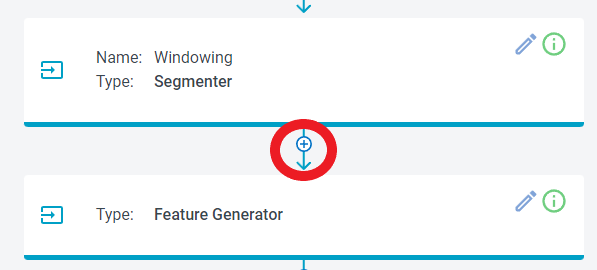
Then
Select Segment Filter
Click +Create
Select Segment Energy Threshold Filter
Set the Threshold to 275
Click Save
This Transform will filter out segments not above a specific threshold, preventing classification from running when the sounds are not loud enough.
Note
Based on the ambient noise and your device sensitivity, you might need to try a different threshold level. Typically, the adopted threshold should be slightly larger than the maximum amplitude of the signal in regions outside the labeled area.
Next, click the edit icon on the Feature Generator. We want to remove all of the features here and only add the MFCC. To do that
Uncheck all of the boxes
Click the Clear Unselected button
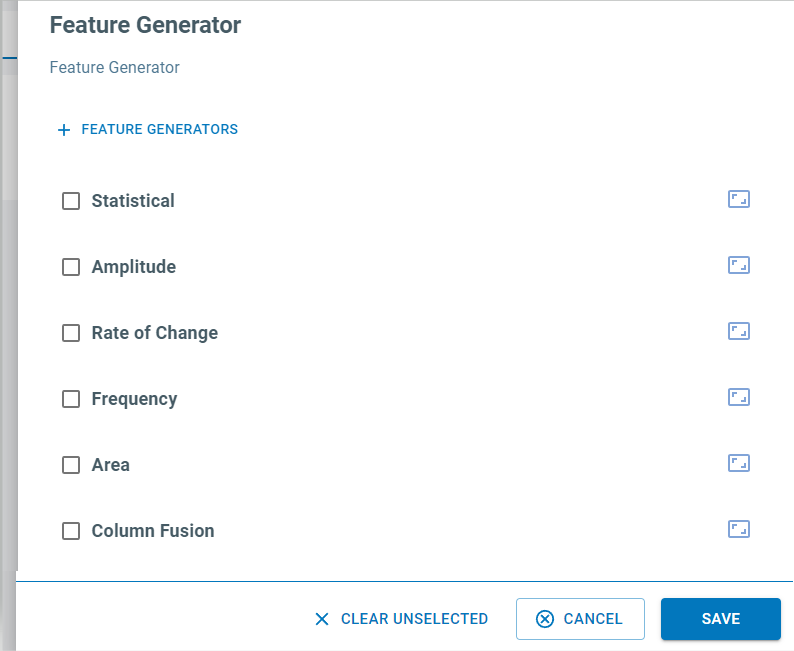
Click on the +Feature Generators button at the top

Expand the Frequency Feature generators
Check the MFCC box

Click the Add button
Click the Save button
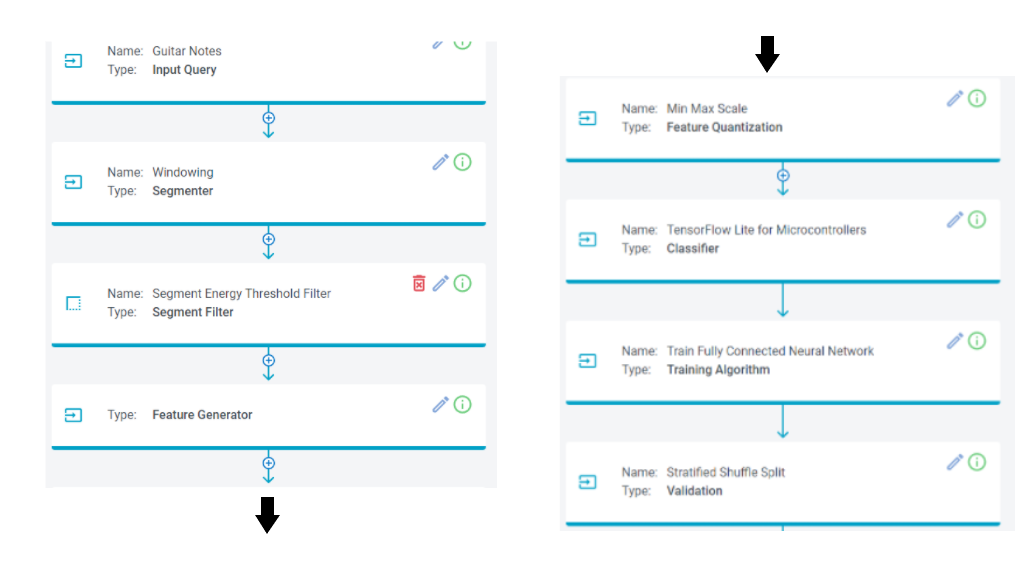
Next, remove the Isolation Forest Filtering Step and the Feature Selector step in the pipeline by clicking the icons.
Your pipeline should now have the following steps.
Click the Run Pipeline button to start training the machine learning model.
You will see some status messages printed in the LOGS on the right side. These can be used to see where the pipeline is in the building process.
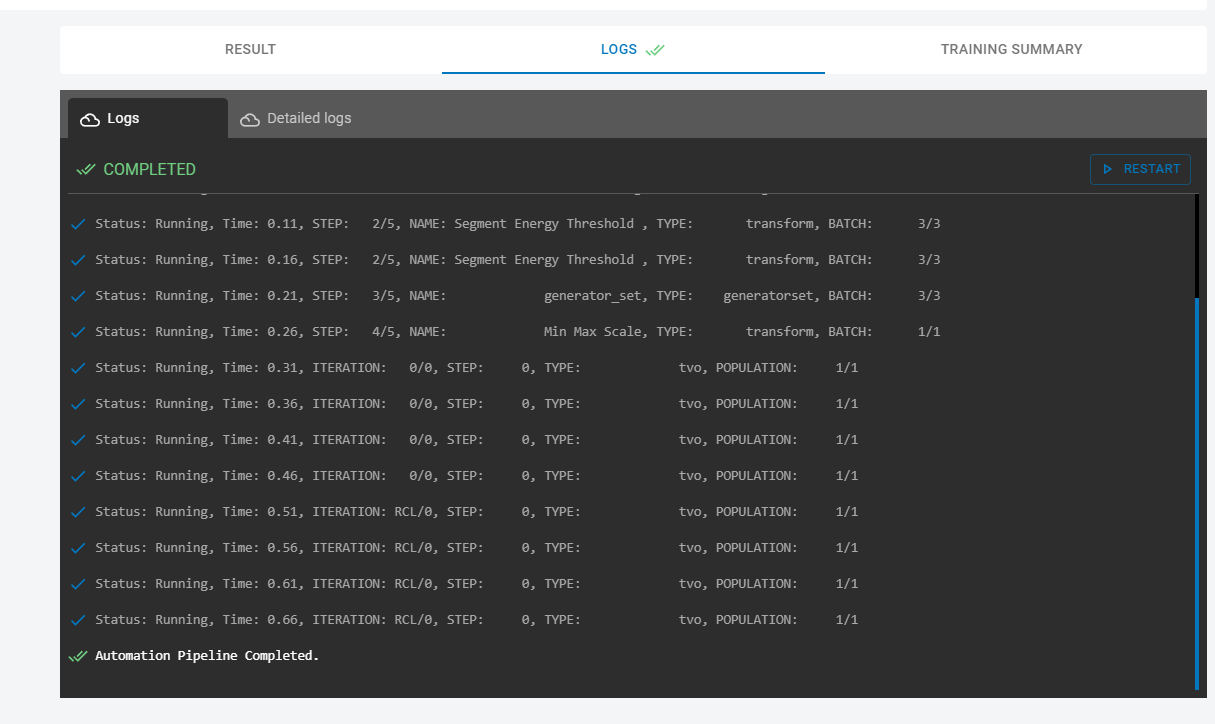
Once the pipeline completes, you will see a model pop up in the Results tab. You can click on the icon to see more detailed information about the model.
Note
Intermediate pipeline steps are stored in a cache. If you change any pipeline step parameters, the pipeline will start from cached values and only steps after your changes will run.
Explore Model
This button will open up the Model Explore tab. The Model Explore tab has information about how the model performed on the training and validation data sets. In this case, the trained model had good accuracy on the cross-fold validation. The final model, however, performed poorly. We will retrain this model with modifications to the pipeline to get better results.
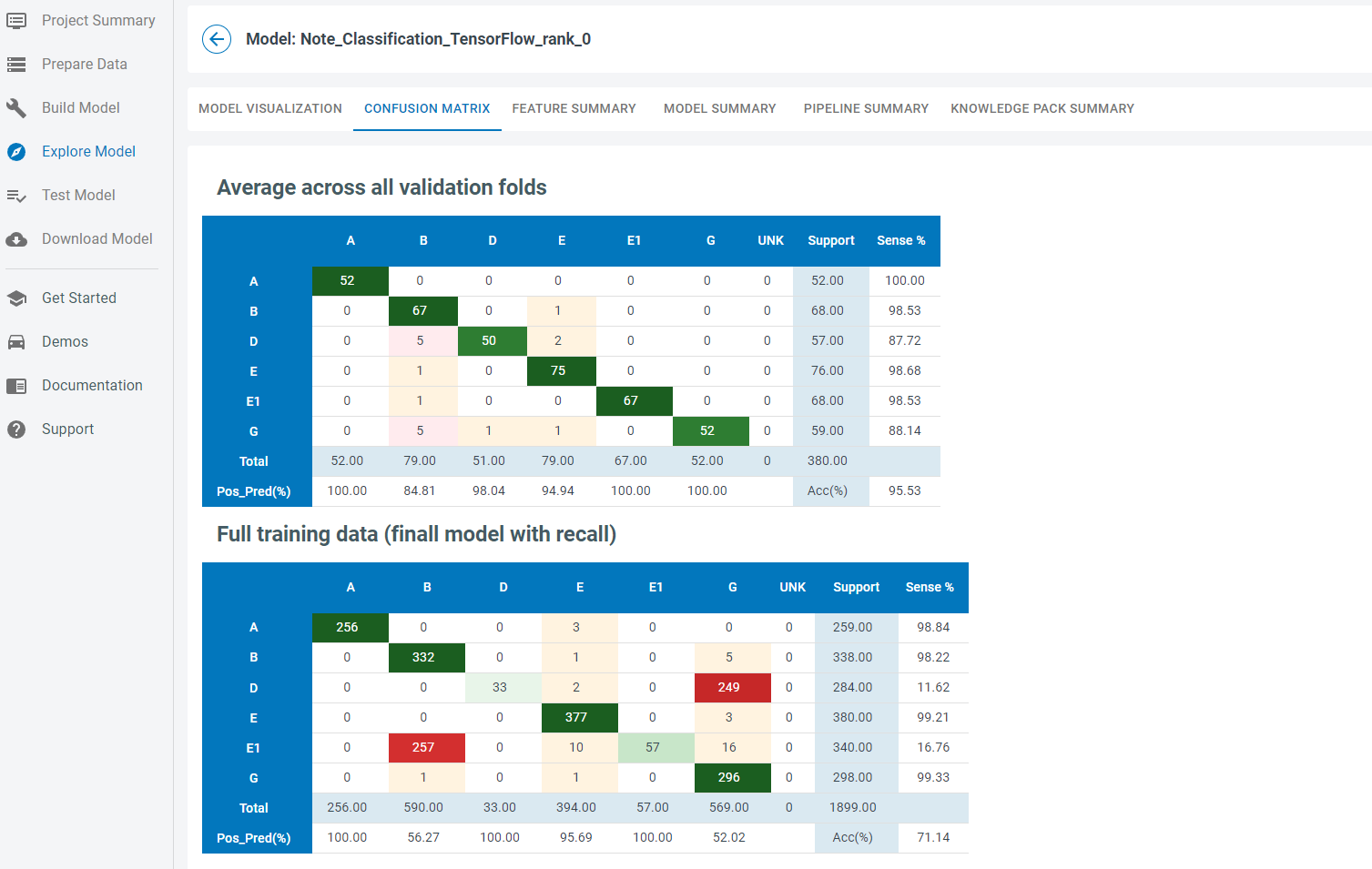
Retrain Model
Go back to the Build Model tab to train a new model. Instead of just retraining, we will increase the duration of time that the model uses. The current pipeline only used a window with 400 samples, a small fraction of the signal. We will create a spectrogram to look at a longer fraction of the audio signal. To do that, add a Feature Cascade step between the Min-Max Scale and the Classifier steps.
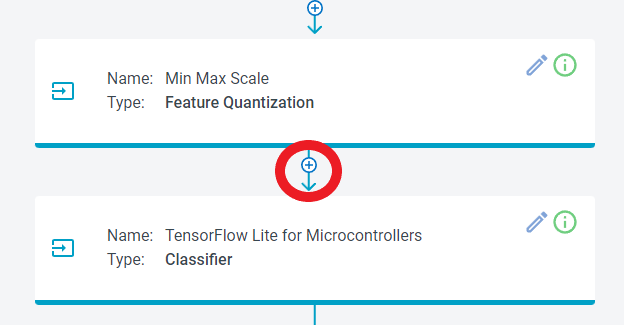
To add the Feature Cascade step to the pipeline
Click the + button
Select Feature Transform
Click the +Create button
Select Feature Cascade
Set Num Cascades to 2
Set Slide to enabled
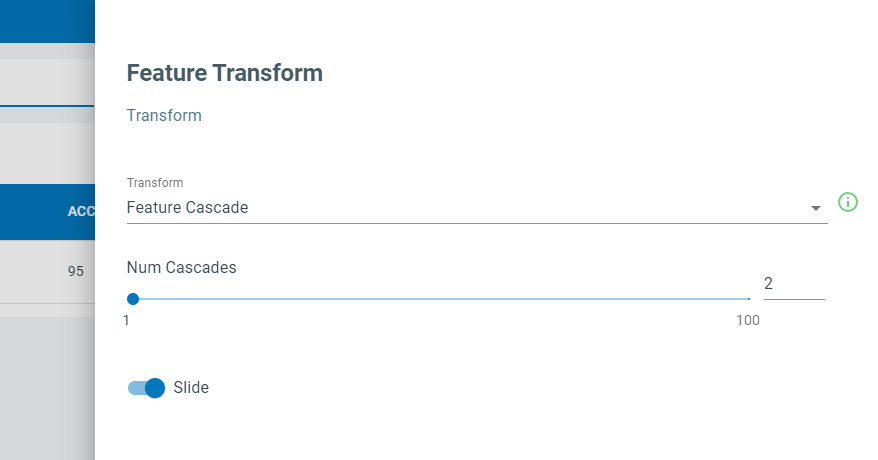
Click the Save button
Setting Num Cascades to 2 feeds data from 800 samples into the classifier. You can calculate this as Num Samples = Window Size x Num Cascades. The features from each segment window are placed into a feature bank. Features banks are stacked together before being fed to the classifier. With Slide enabled, the feature banks will act as a circular buffer, where the last one will be dropped when a new one is added, and classification will occur on every new Feature Bank.
Now that we have made that change, the modified pipeline should look like this.
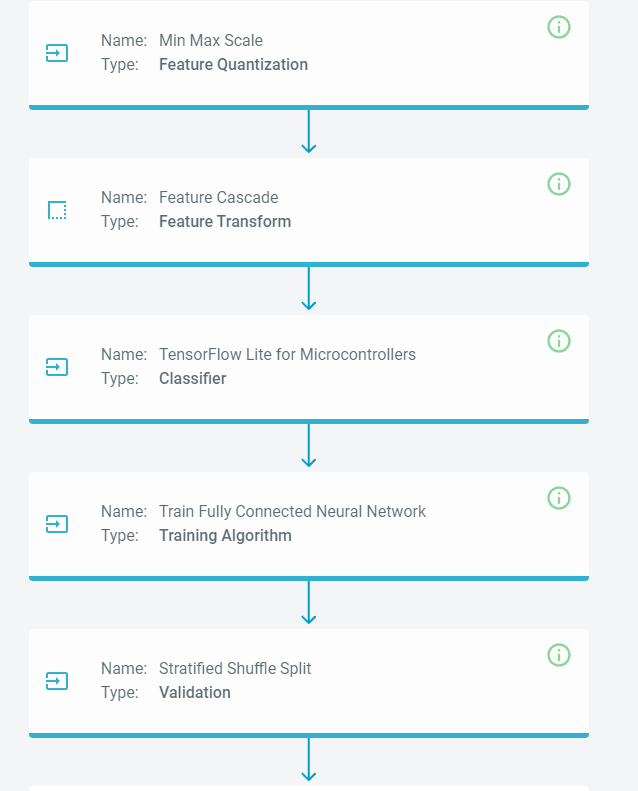
Go ahead and rerun the model training by clicking the Run Pipeline button. You can continue tuning the parameters until you are satisfied with the model.
Model Validation and Testing
Testing a Model in the Analytics Studio
Next, go to the Test Model tab and select the file with metadata Test in Set. This file was excluded from our training data by the Query we created. Then click the Compute Accuracy button to see how the model performs on this capture.
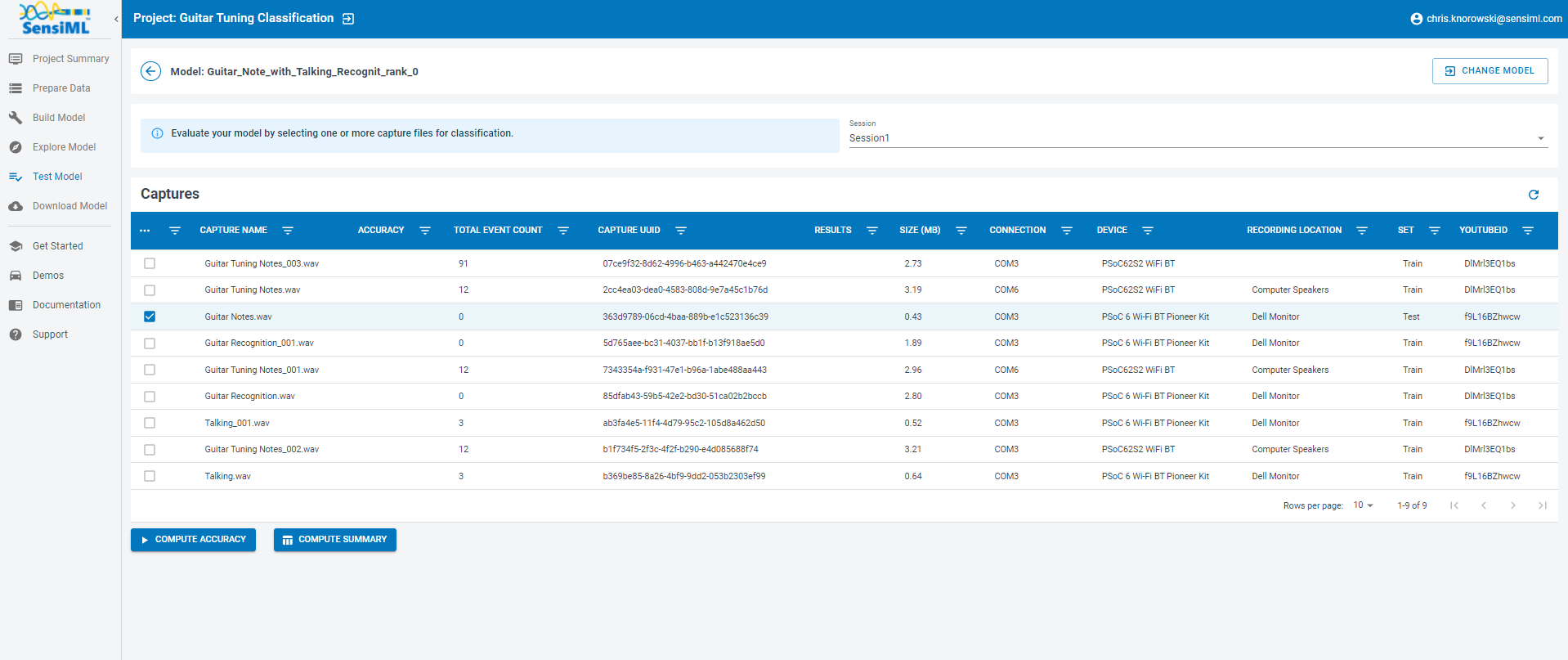
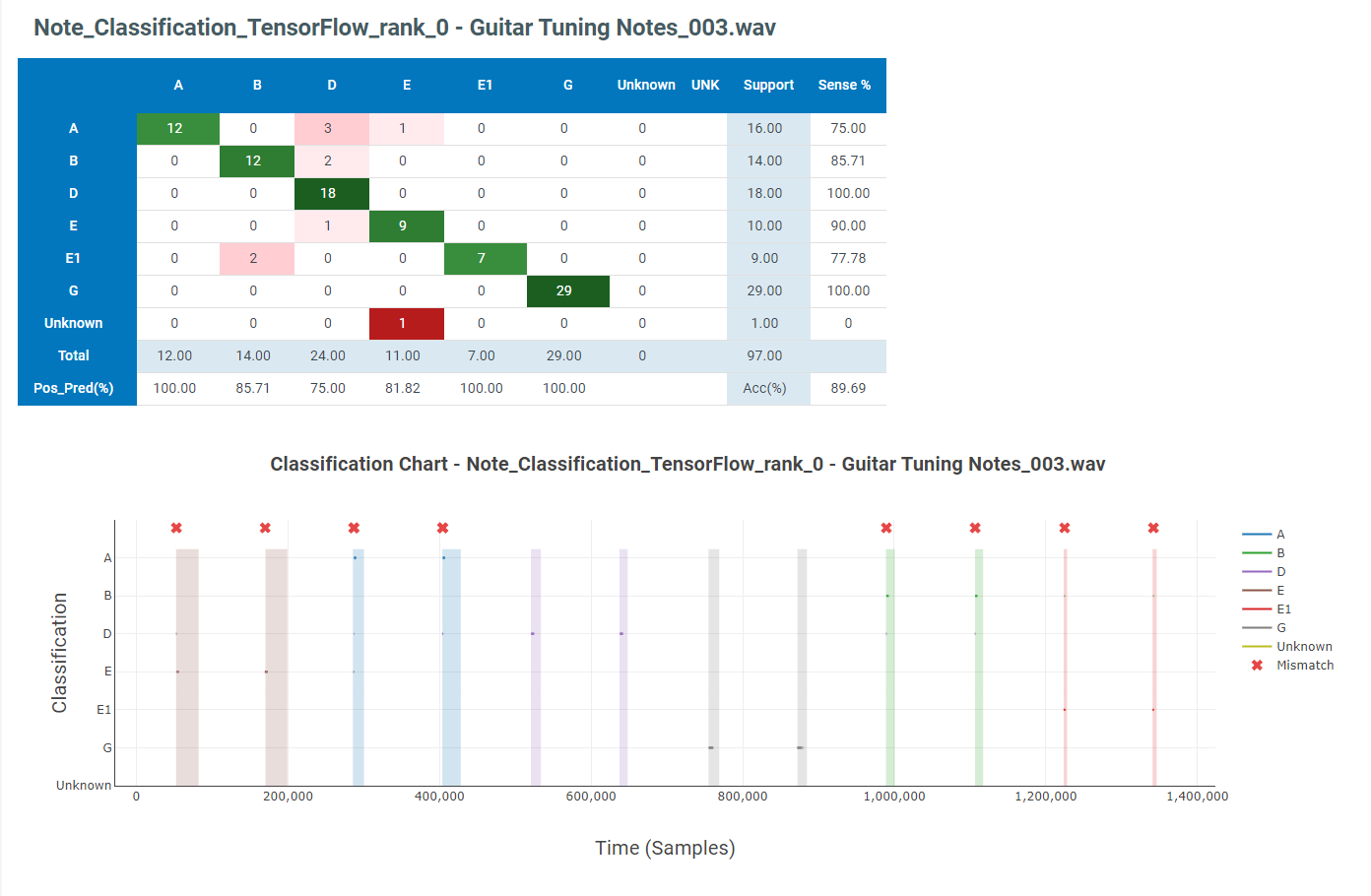
The results of the test will be displayed below. This model performs reasonably well on our test data, and it is worth running it on live data to see how it performs on the device.
Note
You can also run it against multiple files simultaneously and see the combined confusion matrix.
Note
When we run on the device, we will add a post-processing filter that performs majority voting over N classifications. The post-processing filter will remove noise from the classification, improving the overall accuracy.
Running a Model in Real-Time in the Data Studio
Before downloading the Knowledge Pack and deploying it on the device, we can use the Data Studio to view model results in real-time with your data collection firmware.
In the Data Studio, open Test Model mode in the left navigation bar.
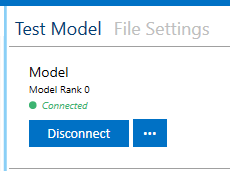
Connect to your model by clicking Connect in the top right
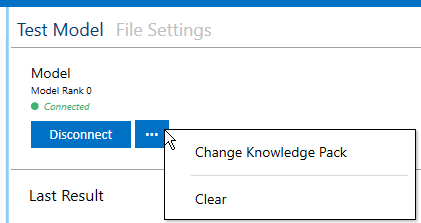
You can change your model by clicking the model options button in the top right.
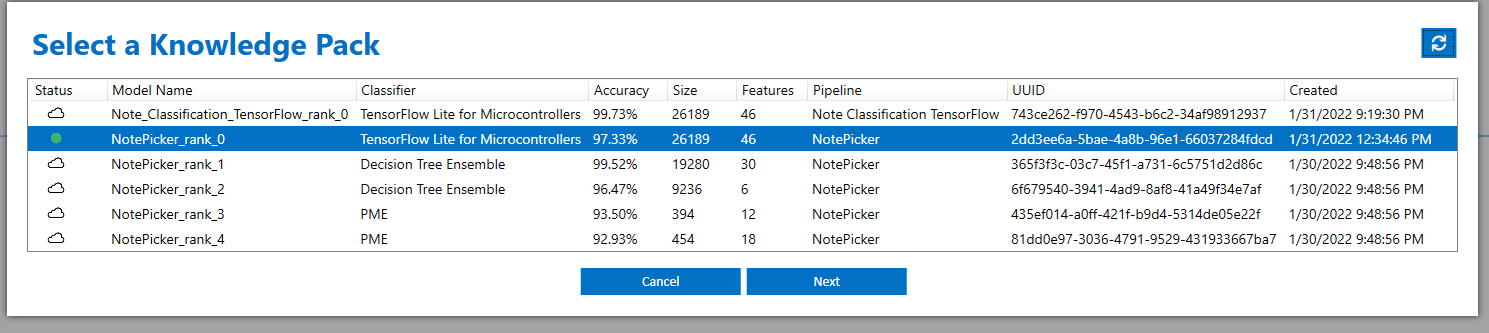
Select the Knowledge Pack you just trained from the table.
Now play the YouTube video, and the Data Studio will run the model against the live stream data. The model classifications results are added to the graph in real-time.
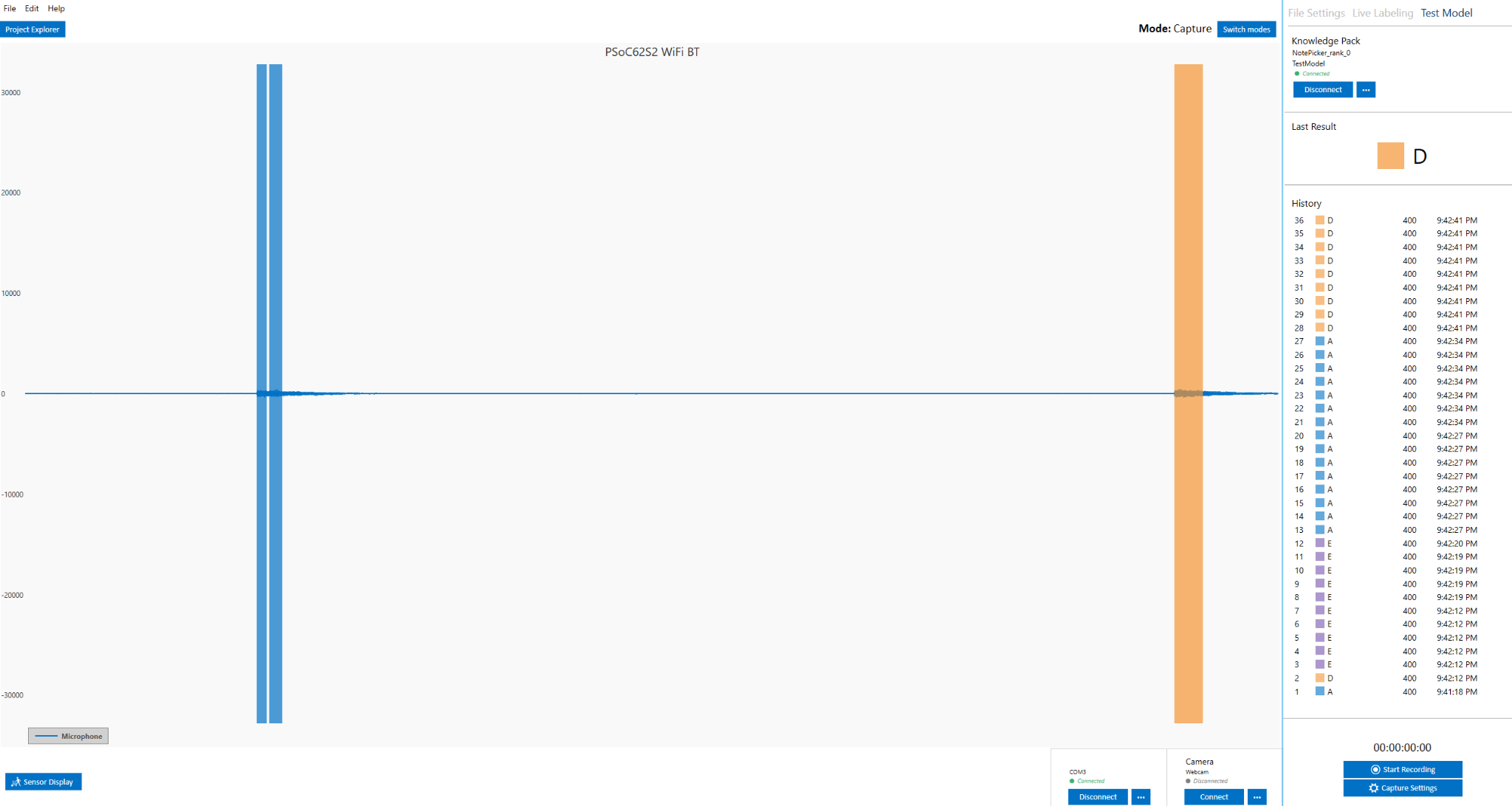
If you are happy with the performance, it is time to put the model onto the device and test its performance in real-time.
Download/Flash Model Firmware
In the Analytics Studio, select your HW platform and download the Knowledge Pack Library.
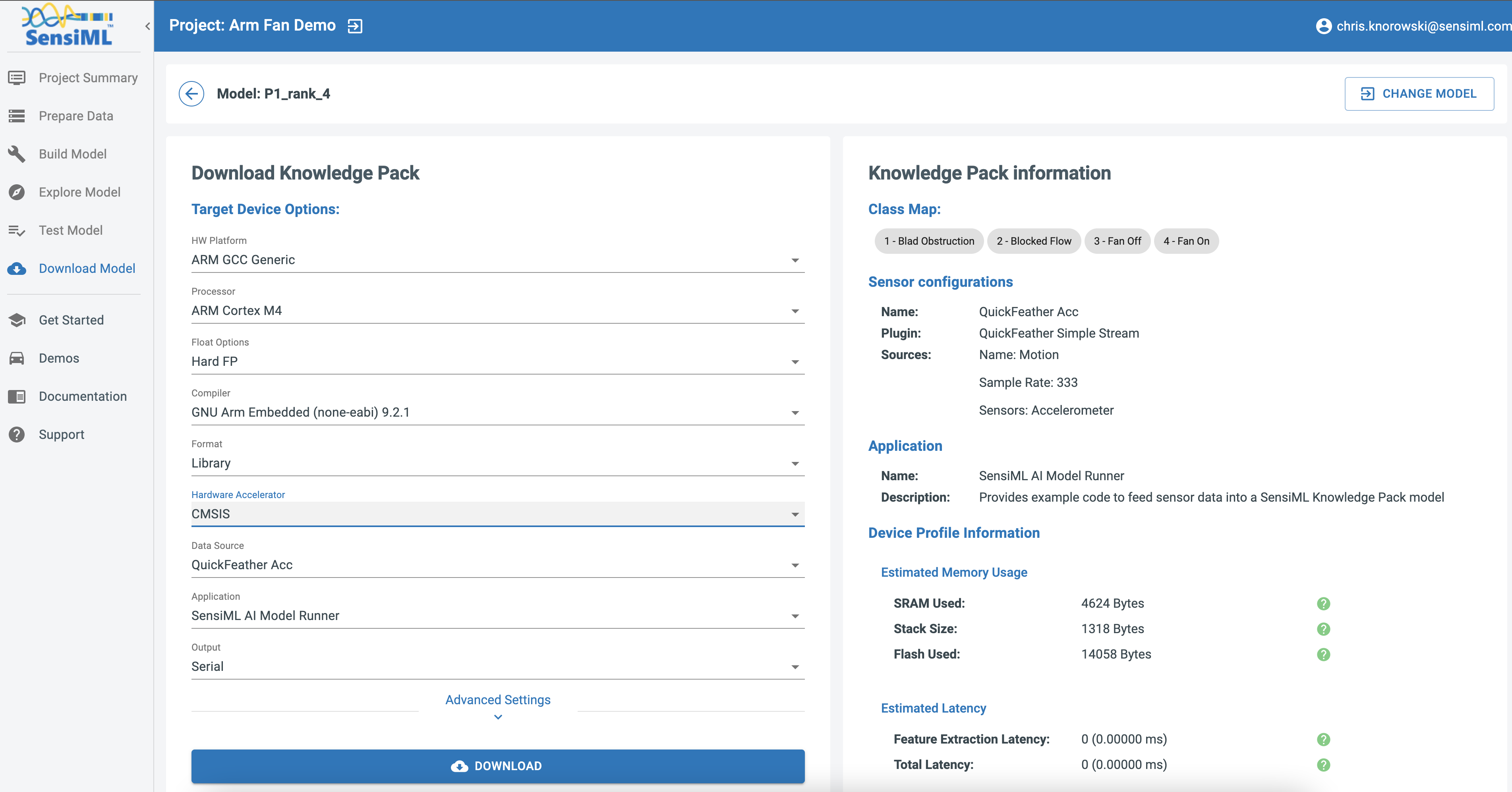
You can find instructions for flashing the Knowledge Pack to your specific device here.
Running a Model in Real-Time on a Device
You can download the compiled version of the Knowledge Pack from the Analytics Studio and flash it to your device firmware.
To see classification results use a terminal emulator such as Tera Term or the SensiML Open Gateway. For additional documentation see running a model on your embedded device.
If you have the Open Gateway installed, start it up, and select the recognition radio button and connection type serial. Scan for the correct COM port and set the baud rate to 1000000. Then Connect to the device.
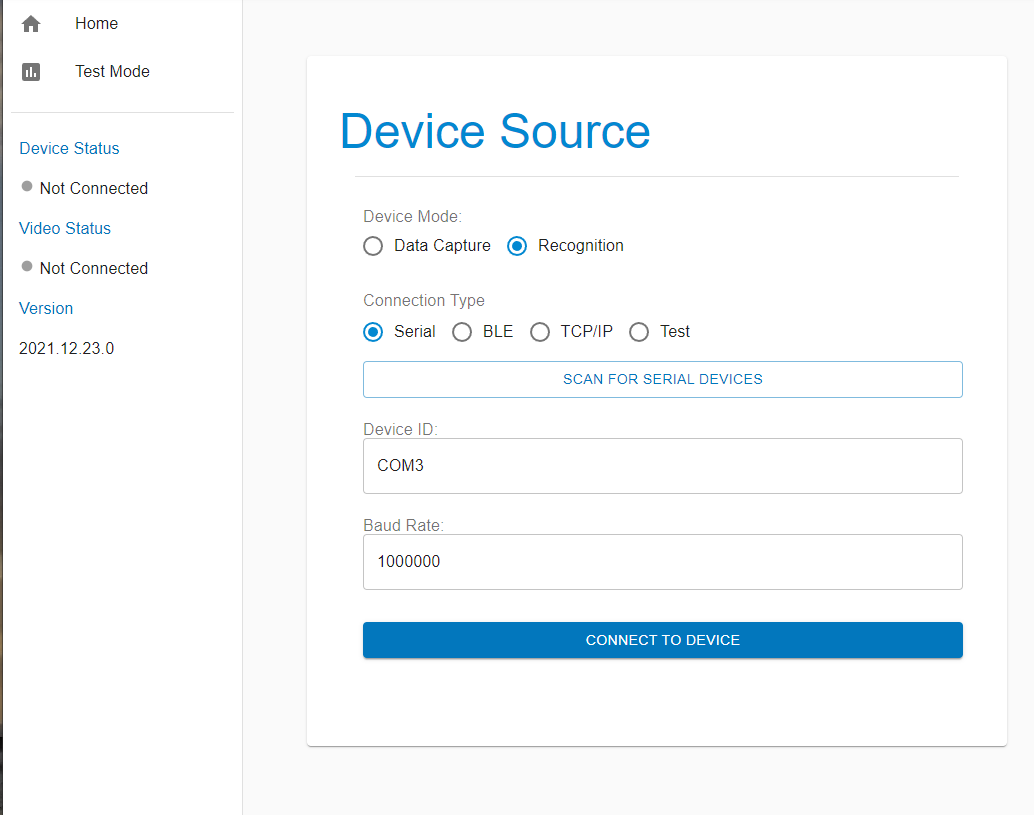
Switch to Test mode, click the Upload Model JSON button and select the model.json file from the Knowledge Pack.
Set the Post Processing Buffer slider to 6 and click the Start Stream button. Then you can play the video and see the model classification from the device in real-time.
