Exploring Model Details
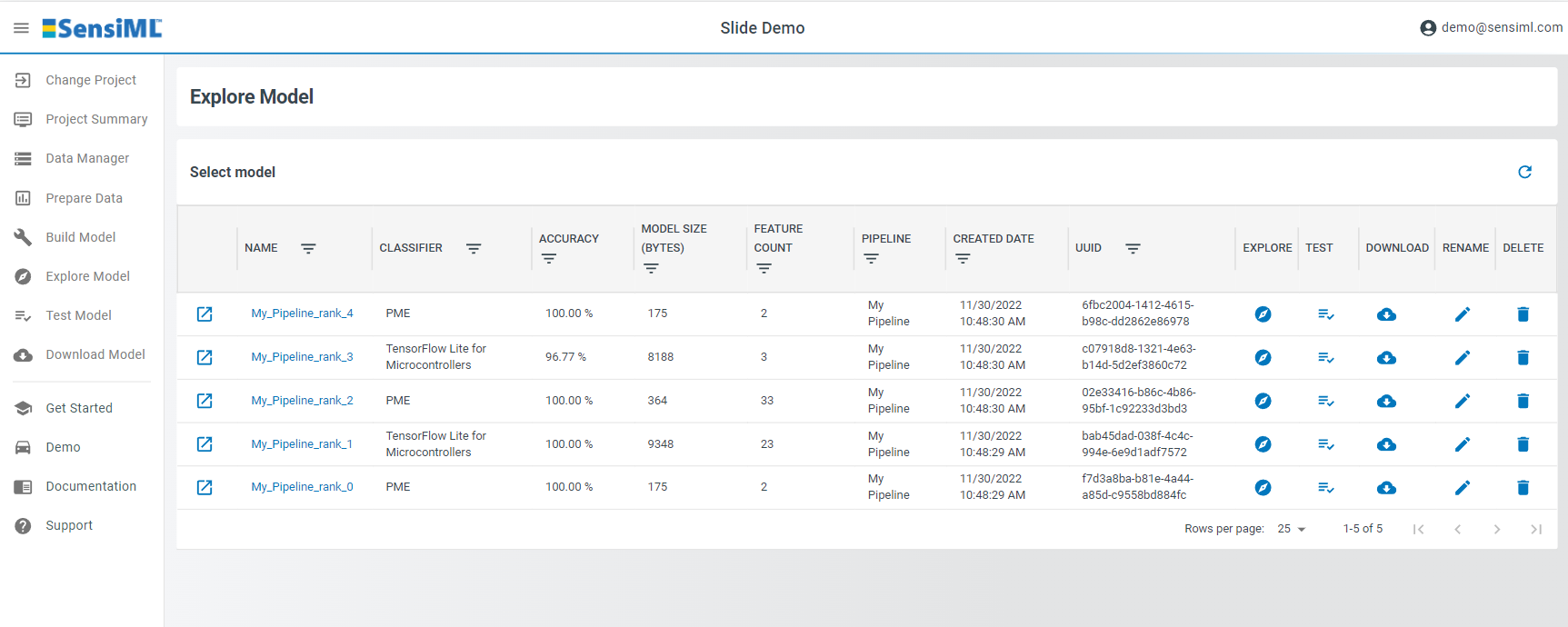
In the Explore Model page you can get more information about the models that were generated from the Build Model page.
Select your model to explore
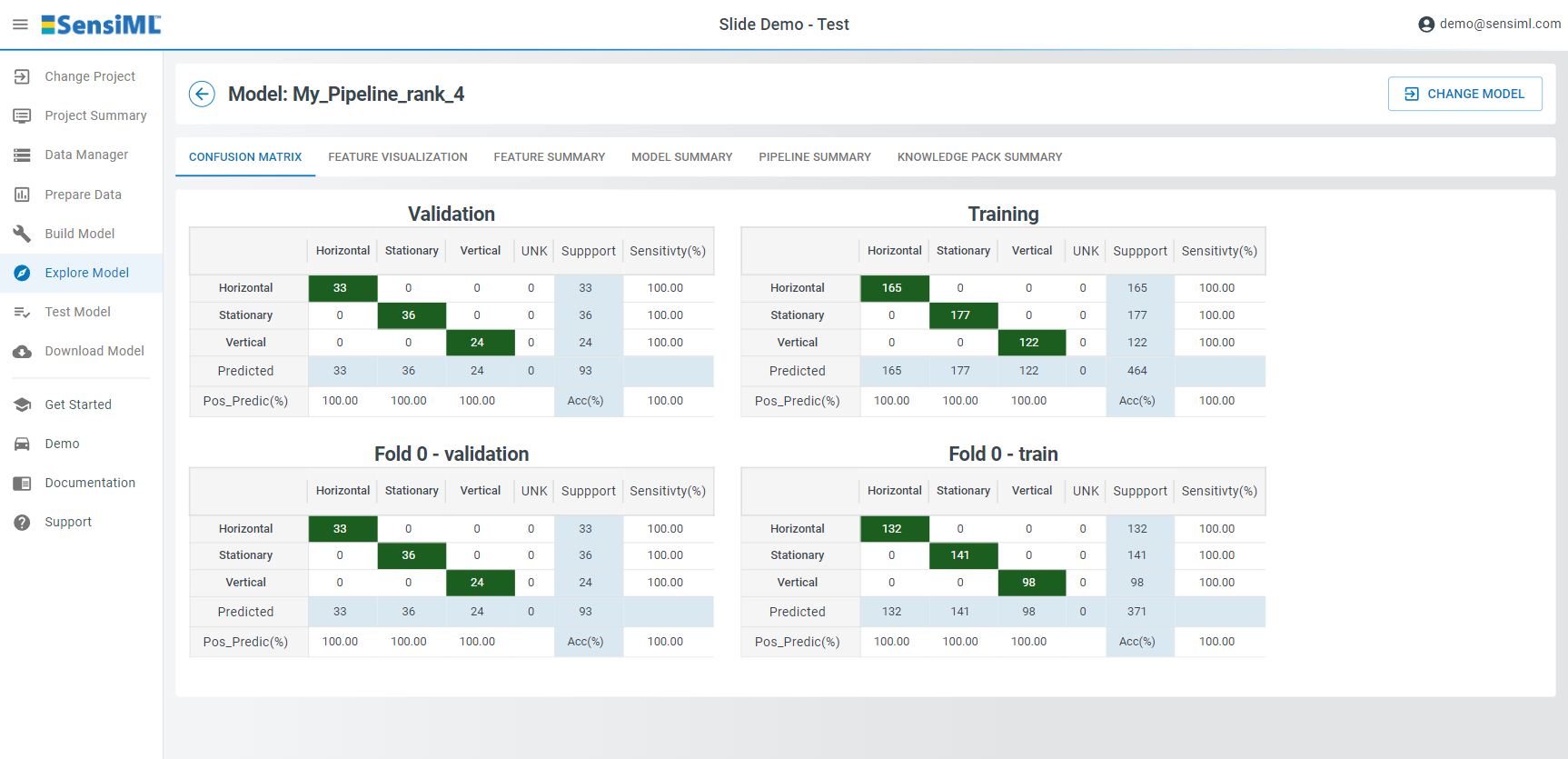
Confusion Matrix
The Confusion Matrix tab shows the averaged confusion matrix for the validation data. The confusion matrix describes how well the model performed at recognizing each class. It also provides information about how the model misclassifies classes. The confusion matrix for models generated by SensiML’s AutoML pipeline is created by averaging across the results of the validation data sets for each fold.
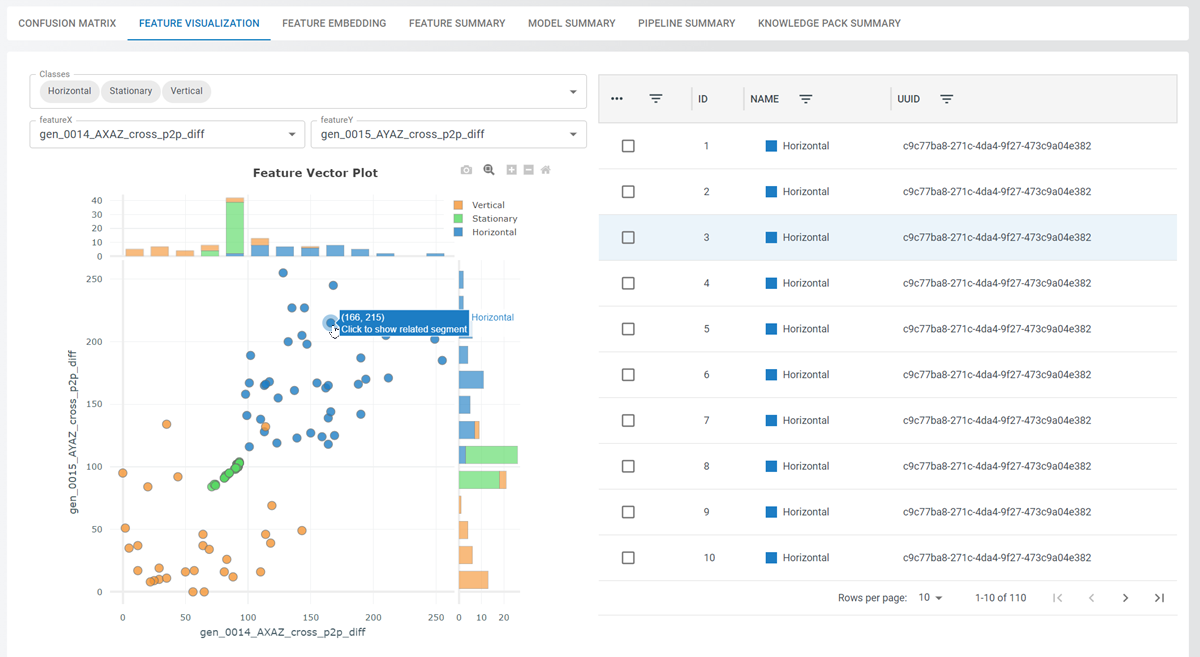
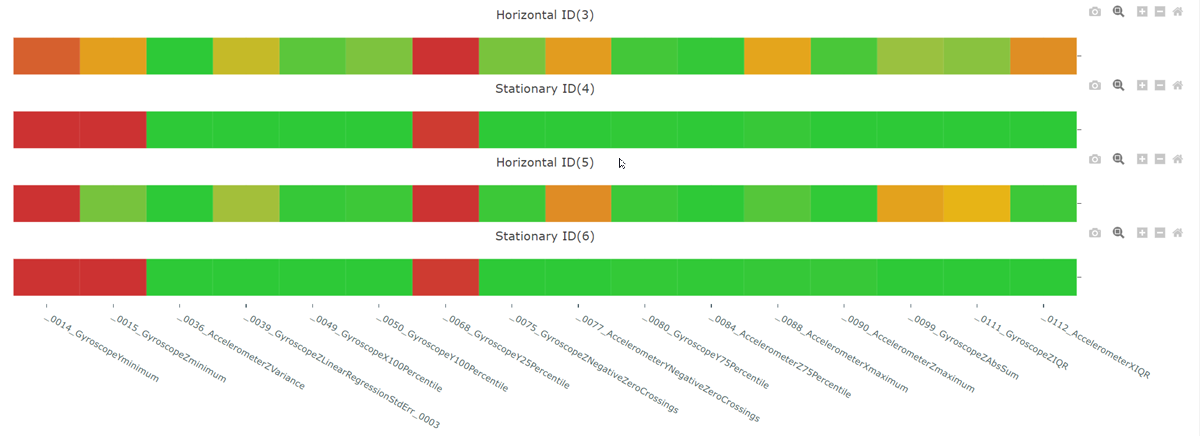
Feature Visualization
The Feature Visualization tab provides feature visualization as a 2-D comparison plot and feature insights chart.
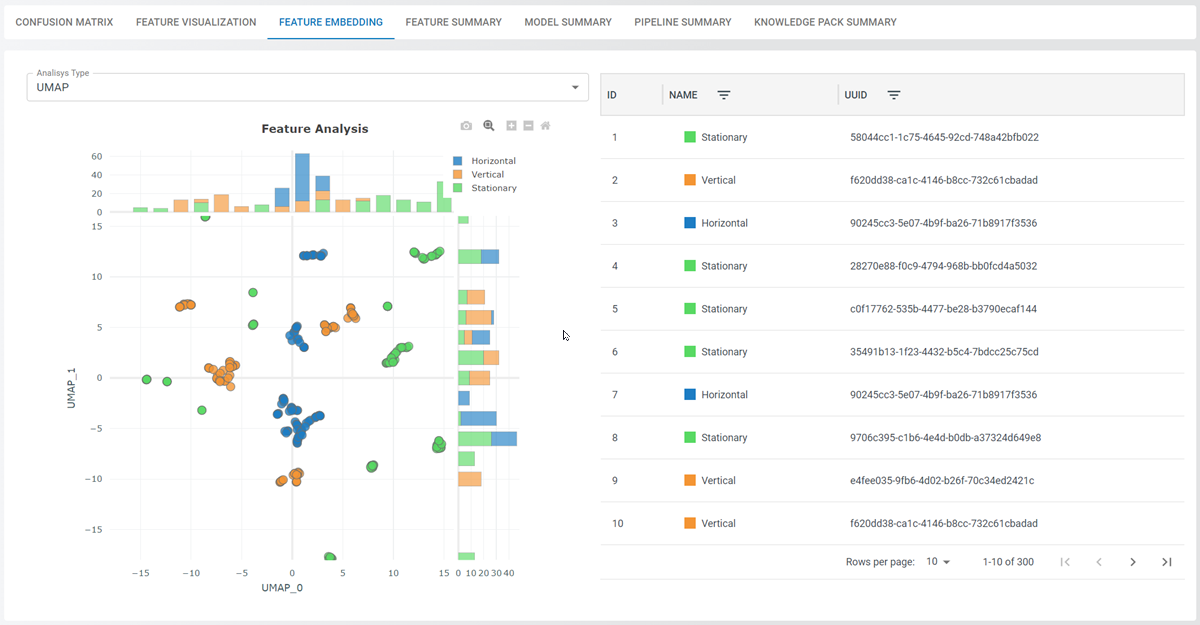
Feature Embedding
The Feature Embedding tab provides three different embedding algorithms: UMAP, PCA, and TSNE. Once you have chosen an embedding algorithm, the Feature Embedding tab will generate a 2-D comparison plot of the embedded features.
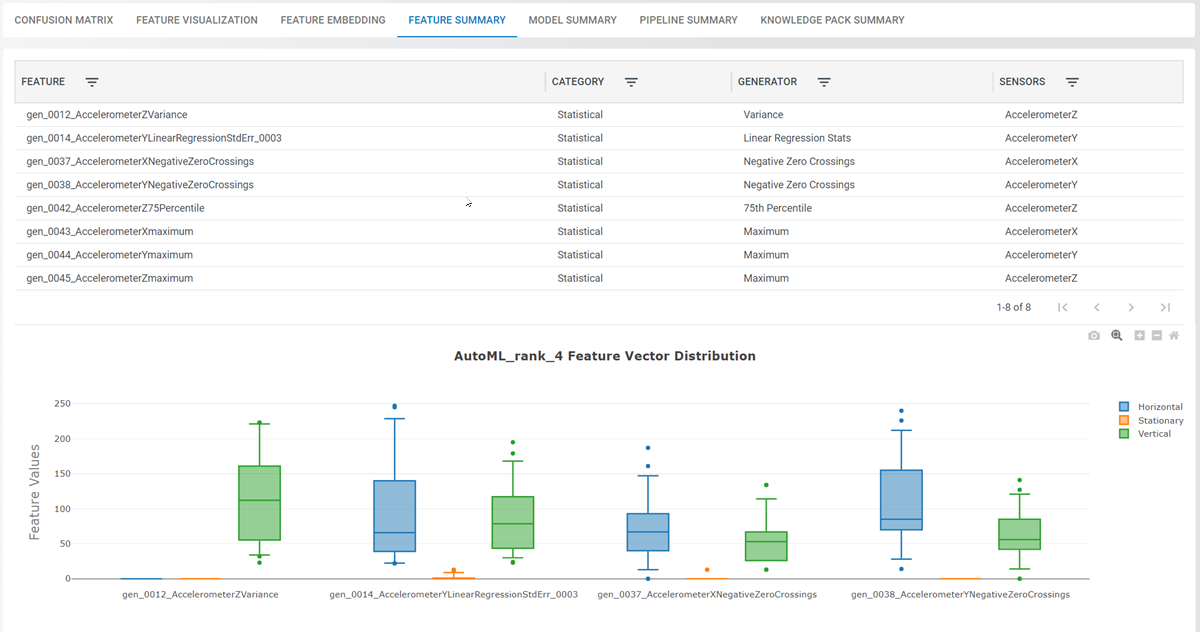
Feature Summary
The Feature Summary tab shows which feature extractors and sensors were used to feed into the model. The Feature Summary tab contains information about the features that are used during the feature extraction step of the Knowledge Pack. This was a simple example project and only needed two feature extractors to generate a high accuracy model. You can see the Category of the feature generator in the first column, which describes the family type to which a feature generator belongs. The Generator column has the name of the feature extractor, which can be used to reference the feature generator when building custom pipelines. The Sensors column describes the sensors that were used as input into this feature extractor.
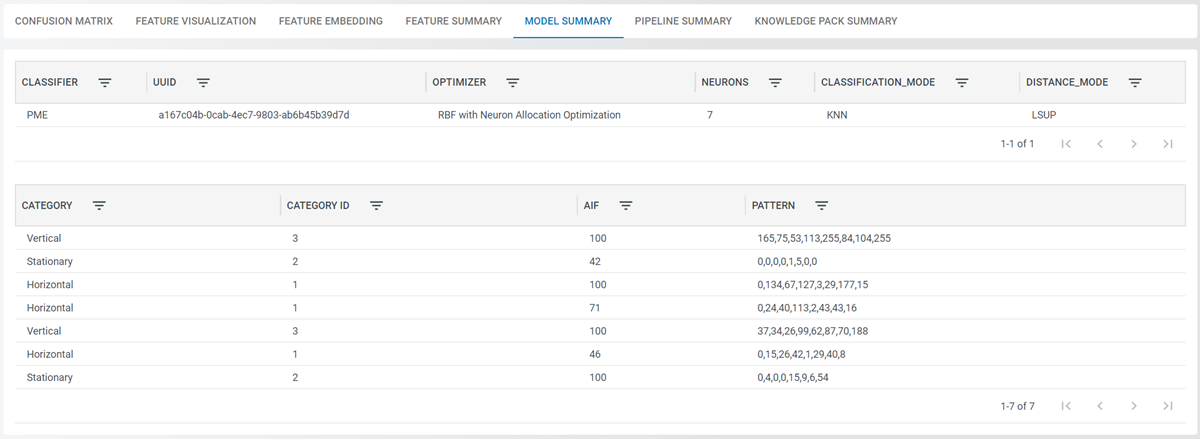
Model Summary
The Model Summary tab describes the classifier, classifier parameters, and training algorithm that was used to generate the final model. In general, this will have information about the classifier name, the training algorithm used to train the model, along with any hyperparameters that were set for training. The uuid field is the unique identifier for this model.
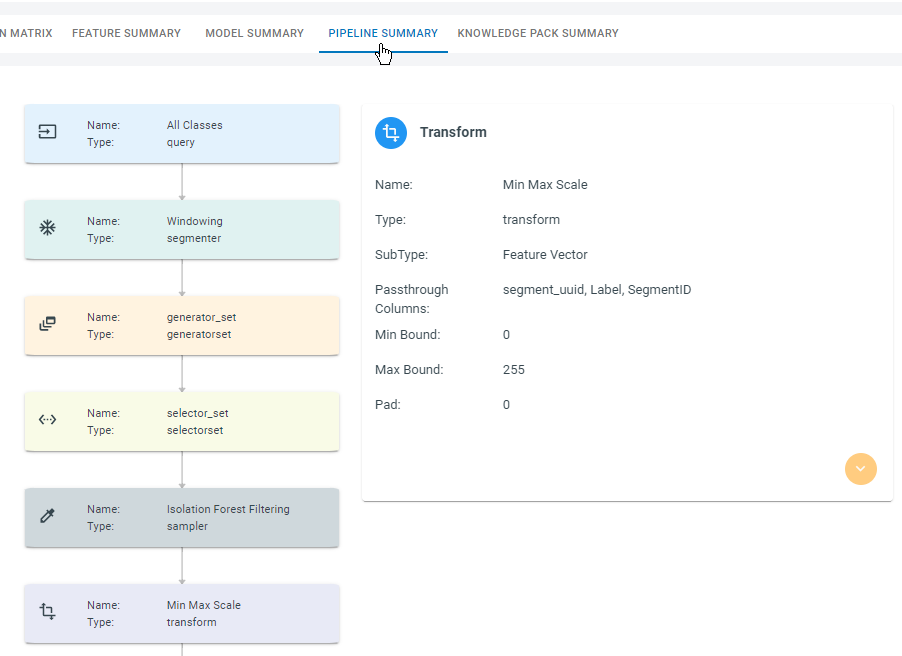
Pipeline Summary
Model pipelines consist of data input, signal conditioning, signal preprocessing, feature extraction, sampling, and model training. The Pipeline Summary provides a graphical representation of the pipeline steps used to create this model. Detailed information about each step is available here.
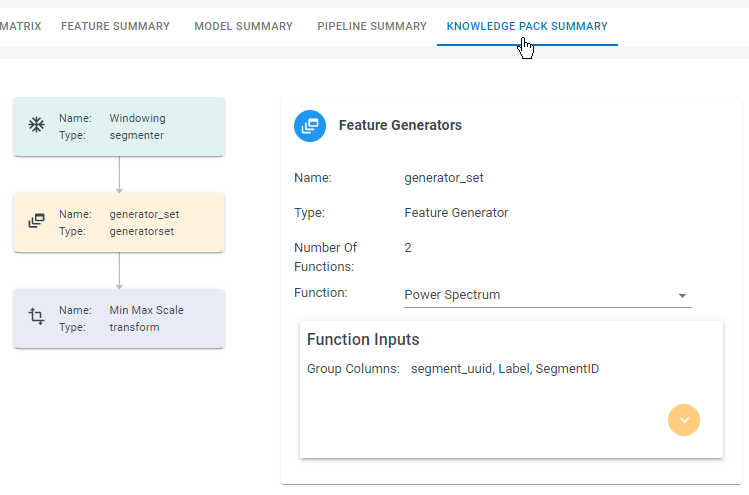
Knowledge Pack Summary
Knowledge Packs consist of data input, signal conditioning, signal preprocessing, feature extraction, and classification. The Knowledge Pack Summary provides the graphical representation of the steps that will be part of the Knowledge Pack. Detailed information about each step is available here.