Using Segmentation Algorithms
In order to build a model with your data you need to be able to break down the incoming signal into segments which can be represented as a feature vector. Selecting the correct segmentation algorithm can be one of the more challenging parts of building a successful pipeline. The trick is to capture segments that contain enough information about the class that you want to recognize while balancing the need to optimize for real-time analytics.
The most basic example of a segmenter is a sliding window. The sliding window is a “naive” segmenter, in that it doesn’t need to know anything about the signal to create a segment. It works by creating a buffer of, say window size 250 data points, and passes that segment to the next steps in your pipeline. Then the window slides a certain distance, such as delta=100, and passes another segment along the pipeline. For certain types of classification, this is all you will need.
However, in many cases you will need more sophisticated segmentation algorithms. For example, instead of passing every segment to your pipeline and eating up battery doing unnecessary calculations you may want to filter out segments that don’t contain useful information. Alternatively, if you are classifying events that occur infrequently, you may want to use a segmenter that only activates when that event occurs so that you can be sure to catch the beginning of the event.
The SensiML Python SDK has segmentation algorithms to help in optimizing your pipeline to select the event areas of a signal. They can be broken down into 3 different categories, filter based, threshold based and key based. In this tutorial we will walk through the different types of segmentation that you can perform.
1. Filter Based
Filter based segmenters use a sliding window and either reject or accept the segments based on certain criteria.
2. Threshold based
These are segmenters that help to identify the start of unique signals. They identify when the signal passes a certain threshold before setting the segment start. After that threshold is passed, a segment of the specified length is created.
3. Key Based
Key segmentation are segmenters that identify segments based on particular actions. These are similar to key words used in products like saying “OK google” to start a query in google now. They are highly customized algorithms that have been tailored to specific use cases.
Try It Yourself
You can download the Notebook file here to follow along with this tutorial in your own environment.
Helper functions to visualize data (execute these cells)
[1]:
import matplotlib.pyplot as plt
%matplotlib inline
def plot_segment(original_data, segmented_data, segment_id=0, axis=['gyroy'], ylim=(-2000,2000)):
if segment_id not in segmented_data.SegmentID.unique():
print("segment id", segment_id, "not in segmented data")
return
seg_start, seg_end = segmented_data[segmented_data.SegmentID==segment_id].iloc[0][['Seg_Begin','Seg_End']].values
if seg_start >= 10:
delta_start = 10
else:
delta_start = 0
original_data[axis].iloc[seg_start-delta_start:seg_end+10].plot(figsize=(16,6), lw=2)
seg_start = [seg_start,seg_start]
seg_end = [seg_end,seg_end]
plt.plot(seg_start, [-max(ylim), max(ylim)],'g',lw=3)
plt.plot(seg_end, [-max(ylim), max(ylim)],'r',lw=3)
plt.ylim(ylim[0], ylim[1])
[2]:
def plot_segmented_data_stream(original_data, segmented_data, axis, ylim=(-5000,5000)):
if 'Seg_Begin' not in segmented_data.columns or 'Seg_End' not in segmented_data.columns:
print('Segmented data does not contain seg start or end, make sure to set "segment_index":True in your segmentation parameters.')
original_data[[axis]].plot(figsize=(16,3))
for seg in segmented_data.Seg_Begin.unique():
plt.plot([seg,seg], [-max(ylim), max(ylim)], 'g', lw=4)
for seg in segmented_data.Seg_End.unique():
plt.plot([seg,seg], [-max(ylim), max(ylim)], 'r', lw=4)
plt.ylim(ylim[0], ylim[1])
Load Your Project
[3]:
from sensiml import SensiML
import pandas as pd
client = SensiML()
client.project = 'Segmentation'
client.pipeline = 'Segmentation Pipeline'
Upload an example CSV file
[4]:
sensor_columns = ['AccelerometerX','AccelerometerY','AccelerometerZ']
data = pd.read_csv('data/pause_detection_data.csv').iloc[:5000]
client.upload_dataframe("pause_gesture.csv", data, force=True)
Uploading file "pause_gesture.csv" to SensiML Cloud.
[4]:
<Response [200]>
Plot the data
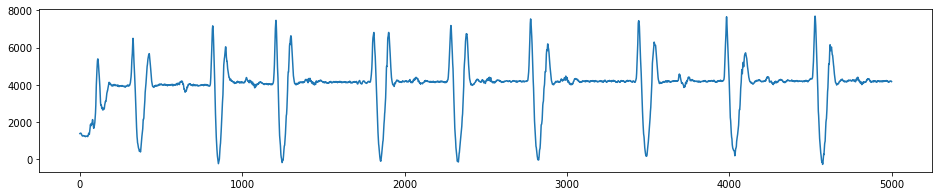
[5]:
data.AccelerometerZ.plot(figsize=(16,3))
[5]:
<AxesSubplot:>
Sliding Window
[6]:
client.pipeline.reset()
client.pipeline.set_input_data('pause_gesture.csv', group_columns=['Subject'], label_column='Class')
client.pipeline.add_transform('Windowing', params={'window_size':100, 'delta':100,'return_segment_index':True})
segmented_data, stats = client.pipeline.execute()
Executing Pipeline with Steps:
------------------------------------------------------------------------
0. Name: pause_gesture.csv Type: featurefile
------------------------------------------------------------------------
------------------------------------------------------------------------
1. Name: Windowing Type: segmenter
------------------------------------------------------------------------
------------------------------------------------------------------------
Results Retrieved... Execution Time: 0 min. 0 sec.
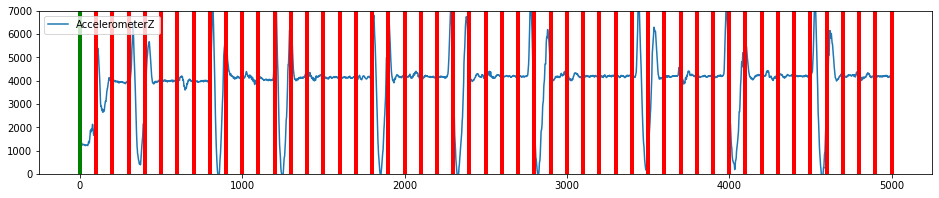
Plot the Data
Create a plot of all the segmented data, green is start of segment, red is the end of the segment.
[7]:
plot_segmented_data_stream(data, segmented_data, 'AccelerometerZ', ylim=(0,7000))
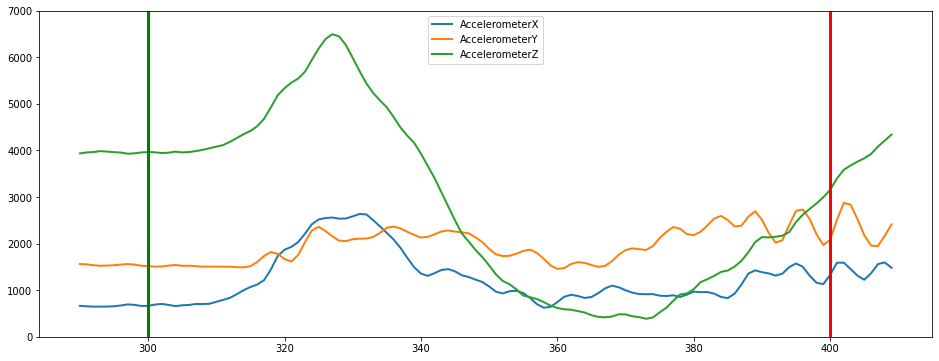
Plot a segment
Create a plot of a single segment
[8]:
plot_segment(data, segmented_data, segment_id=3, axis=['AccelerometerX','AccelerometerY','AccelerometerZ'], ylim=(0,7000))
Threshold Based Segmentation
General Threshold Algorithm
The general threshold algorithm is a customizable threshold algorithm that allows you to flexibly specify many of the parameters. In technical terms we compute a threshold space use a sliding window on the axis you choose transforming the original timeseries domain into one of the following (standard deviation, absolute sum, sum, variance, absolute average). This is a general algorithm than can be tuned to suit a variety of applications, particularly in cases where events are well separated in time domain.
[9]:
data.AccelerometerZ.plot(figsize=(16,3), ylim=(-1000,10000))
[9]:
<AxesSubplot:>
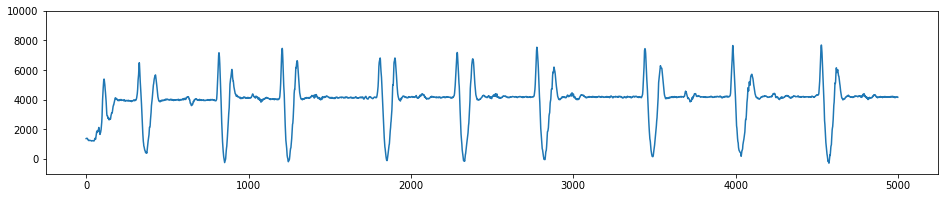
[10]:
client.pipeline.reset()
client.pipeline.set_input_data('pause_gesture.csv', group_columns=['Subject'], label_column='Class')
Add the Pause-Peak Algorithm to the segmentation pipeline
[11]:
#Applying windowing thresholding
client.pipeline.add_transform('General Threshold Segmentation', params={'first_column_of_interest': 'AccelerometerZ',
'second_column_of_interest': 'AccelerometerZ',
'max_segment_length':225,
'min_segment_length':125,
'first_vt_threshold':600.,
'second_vt_threshold':150.,
'first_comparison':'max',
'second_comparison':'min',
'threshold_space_width':25,
'first_threshold_space':'std',
'second_threshold_space':'std',
'return_segment_index':True
}
)
segmented_data, stats = client.pipeline.execute()
Executing Pipeline with Steps:
------------------------------------------------------------------------
0. Name: pause_gesture.csv Type: featurefile
------------------------------------------------------------------------
------------------------------------------------------------------------
1. Name: General Threshold Segmentation Type: segmenter
------------------------------------------------------------------------
------------------------------------------------------------------------
Results Retrieved... Execution Time: 0 min. 0 sec.
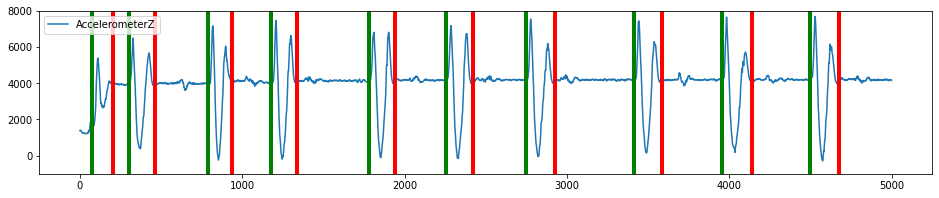
As you can see multiple segments were recognized. The green is the start of a segment and the red is the end of the segment.
[12]:
plot_segmented_data_stream(data, segmented_data, 'AccelerometerZ', ylim=(-1000,8000))
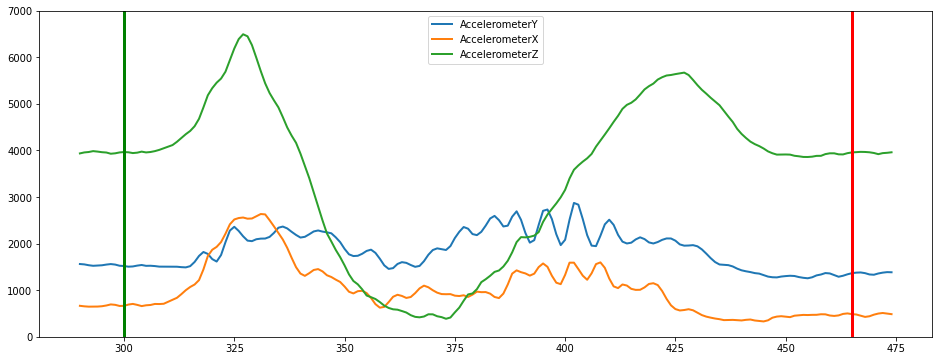
the following plot allows you to look at individual segments and see multiple data streams from the original data.
[13]:
plot_segment(data, segmented_data, segment_id=1, axis=['AccelerometerY', 'AccelerometerX','AccelerometerZ'], ylim=(0,7000))
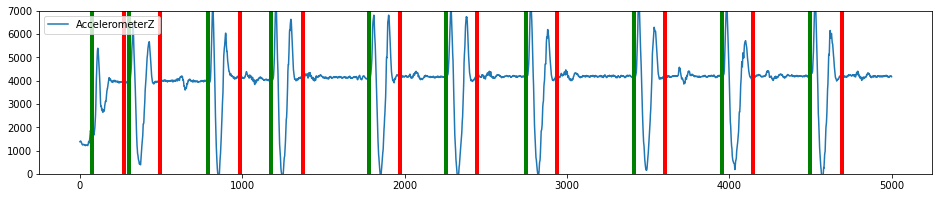
Windowing Threshold Algorithm
The windowing threshold algorithm is a customizable threshold algorithm that allows you to flexibly specify many of the parameters. In technical terms we compute a threshold space use a sliding window on the axis you choose transforming the original timeseries domain into one of the following (standard deviation, absolute sum, sum, variance, absolute average). This is a general algorithm than can be tuned to suit a variety of applications, particularly in cases where events are well separated in time domain. It is different from the General Threshold Algorithm in that as soon as it detects a point above the threshold value, it will create a window of a set size. This is a very simple segmentation algorithm that can be good for detecting events quickly, but is not great at detecting the correct duration of the event.
[14]:
client.pipeline.reset()
client.pipeline.set_input_data('pause_gesture.csv', group_columns=['Subject'], label_column='Class')
#Applying windowing thresholding
client.pipeline.add_transform('Windowing Threshold Segmentation', params={'column_of_interest': 'AccelerometerZ',
'window_size':195,
'delta':196,
'vt_threshold':600.0,
'threshold_space_width':25,
'threshold_space':'std',
'return_segment_index':True
}
)
segmented_data, stats = client.pipeline.execute()
Executing Pipeline with Steps:
------------------------------------------------------------------------
0. Name: pause_gesture.csv Type: featurefile
------------------------------------------------------------------------
------------------------------------------------------------------------
1. Name: Windowing Threshold Segmentation Type: segmenter
------------------------------------------------------------------------
------------------------------------------------------------------------
Results Retrieved... Execution Time: 0 min. 0 sec.
[15]:
plot_segmented_data_stream(data, segmented_data, 'AccelerometerZ', ylim=(0,7000))
Filter Based Segmentation
Windowing can be used on its own or with a filter. Next we will show how to use a filter.
[16]:
client.pipeline.reset()
client.pipeline.set_input_data('pause_gesture.csv', group_columns=['Subject'], label_column='Class')
client.pipeline.add_transform('Windowing', params={'window_size':100, 'delta':100, 'return_segment_index':True})
window_segmented_data, stats = client.pipeline.execute()
Executing Pipeline with Steps:
------------------------------------------------------------------------
0. Name: pause_gesture.csv Type: featurefile
------------------------------------------------------------------------
------------------------------------------------------------------------
1. Name: Windowing Type: segmenter
------------------------------------------------------------------------
------------------------------------------------------------------------
Results Retrieved... Execution Time: 0 min. 0 sec.
[17]:
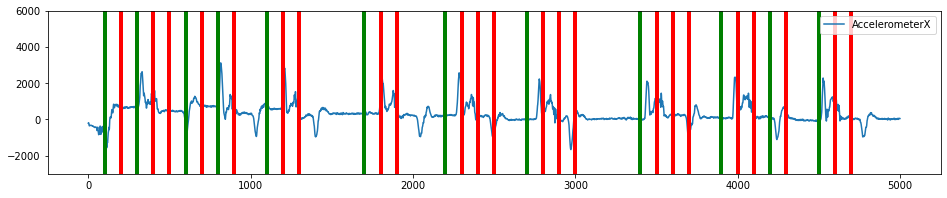
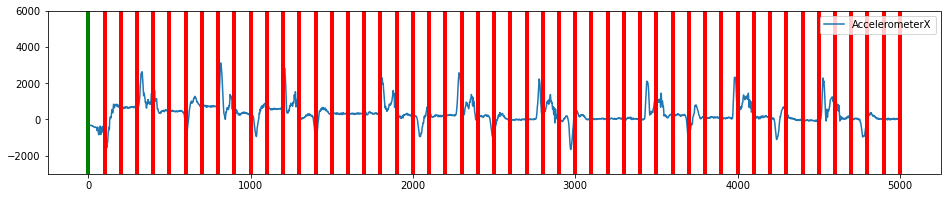
plot_segmented_data_stream(data, window_segmented_data, 'AccelerometerX', ylim=(-3000,6000))
Add a Segment Energy Threshold filter
[18]:
client.pipeline.reset()
client.pipeline.set_input_data('pause_gesture.csv', group_columns=['Subject'], label_column='Class')
client.pipeline.add_transform('Windowing', params={'window_size':100, 'delta':100})
client.pipeline.add_transform("Segment Energy Threshold Filter", params={"input_column": 'AccelerometerX',
"threshold":1000})
segmented_data, stats = client.pipeline.execute()
Executing Pipeline with Steps:
------------------------------------------------------------------------
0. Name: pause_gesture.csv Type: featurefile
------------------------------------------------------------------------
------------------------------------------------------------------------
1. Name: Windowing Type: segmenter
------------------------------------------------------------------------
------------------------------------------------------------------------
2. Name: Segment Energy Threshold Filter Type: transform
------------------------------------------------------------------------
------------------------------------------------------------------------
Results Retrieved... Execution Time: 0 min. 0 sec.
Plot the filtered results
[19]:
filtered_segments = window_segmented_data[window_segmented_data.SegmentID.isin(segmented_data.SegmentID.unique())]
plot_segmented_data_stream(data, filtered_segments, 'AccelerometerX', ylim=(-3000,6000))